Faktory ovplyvňujúce adaptáciu žiakov prvého stupňa
Adaptačné obdobie prvákov je dôležitým krokom v ich kognitívnom a učebnom procese. Rodičia, učitelia a...
Pri veľkom počte pozorovaní nie sú vhodné hierarchické metódy zhlukovej analýzy. V takýchto prípadoch sa používajú nehierarchické metódy založené na delení, ktoré sú iteračné metódy rozdelenie pôvodného obyvateľstva. Počas procesu delenia sa vytvárajú nové zhluky až do pravidlo zastavenia.
Takéto nehierarchické zhlukovanie spočíva v rozdelení súboru údajov na určité množstvo jednotlivé zhluky. Sú dva prístupy. Prvým je definovanie hraníc zhlukov ako najhustejších oblastí vo viacrozmernom priestore počiatočných údajov, t.j. definícia zhluku, kde je veľká „koncentrácia bodov“. Druhým prístupom je minimalizovať mieru rozdielu objektov
Najčastejšie medzi nehierarchickými metódami algoritmus k-means, tiež nazývaný rýchla zhluková analýza. Kompletný popis algoritmu možno nájsť v Hartigan a Wong (1978). Na rozdiel od hierarchických metód, ktoré nevyžadujú predbežné predpoklady o počte zhlukov, aby bolo možné túto metódu použiť, je potrebné mať hypotézu o najpravdepodobnejšom počte zhlukov.
algoritmus k-means
vytvára k zhlukov umiestnených v najväčšej možnej vzdialenosti od seba. Hlavný typ problémov, ktoré sa riešia algoritmus k-means, - prítomnosť predpokladov (hypotéz) týkajúcich sa počtu zhlukov, pričom by sa mali čo najviac líšiť. Voľba čísla k môže byť založená na predchádzajúcom výskume, teoretických úvahách alebo intuícii.Všeobecná myšlienka algoritmu: daný pevný počet k pozorovacích klastrov sa porovnáva so klastrami tak, aby sa priemery v klastri (pre všetky premenné) od seba čo najviac líšili.
Vyberie sa číslo k a v prvom kroku sa tieto body považujú za „stredy“ zhlukov. Každý zhluk zodpovedá jednému centru.
Je možné vykonať výber počiatočných ťažísk nasledujúcim spôsobom:
Výsledkom je, že každý objekt je priradený ku konkrétnemu zhluku.
Sú vypočítané klastrové centrá, čo sú potom a nižšie súradnicové priemery zhlukov. Objekty sa opäť prerozdelia.
Proces výpočtu stredísk a prerozdeľovania objektov pokračuje, kým nie je splnená jedna z nasledujúcich podmienok:
Na obr. 14.1 je príklad práce algoritmus k-means pre k sa rovná dvom.
Ryža. 14.1.
Výber počtu klastrov je zložitá otázka. Ak neexistujú žiadne predpoklady o tomto čísle, odporúča sa vytvoriť 2 klastre, potom 3, 4, 5 atď., pričom sa porovnávajú výsledky.
Klastrová analýza je štatistická analýza, ktorá umožňuje rozdeliť veľké množstvo údajov do tried alebo skupín (z angličtiny, zhluk- trieda) podľa nejakého kritéria alebo ich kombinácie.
Na klasifikáciu údajov X x,...,X str použite pojem metriky alebo vzdialenosti.
metrický je funkcia p, ktorá mapuje nejaký metrický priestor do priestoru reálnych čísel a má nasledujúce vlastnosti (metrické axiómy):
Teória zhlukovej analýzy používa na meranie vzdialenosti medzi jednotlivými bodmi (vektormi) nasledujúce metriky:
1) Euklidovská vzdialenosť
2) vážená euklidovská vzdialenosť

Kde týždeň - váhy úmerné dôležitosti znaku v klasifikačnom probléme. Váhy sú stanovené po dodatočnom výskume
a predpokladajme, že ^ w* = 1;

4) Mahalanobisova vzdialenosť (alebo Mahalanobisov uhol)
kde A je symetrická pozitívne definitná matica hmotnostné koeficienty(často zvolená uhlopriečka); A - vektorová kovariančná matica X19..., Xp;
5) Minkowského vzdialenosť

Vzdialenosti 1), 2), 3) alebo 5) sa používajú v prípade normálneho rozdelenia nezávislých náhodných premenných X l9 ...,X n ~N(M,A) alebo v prípade ich homogenity v geochemickom zmysle, keď je každý vektor pre klasifikáciu rovnako dôležitý. Vzdialenosť 4) sa používa, ak existuje kovariančný vzťah vektorov X x,...,X P.
Výber metriky vykonáva výskumník v závislosti od toho, aký výsledok chce získať. Táto voľba nie je formalizovaná, pretože závisí od mnohých faktorov, najmä od očakávaného výsledku, od skúseností výskumníka, úrovne jeho matematickej prípravy atď.
V mnohých algoritmoch sa spolu so vzdialenosťami medzi vektormi používajú aj vzdialenosti medzi klastrami a spojenia klastrov.
Nechaj S(- /-tý zhluk, pozostávajúci z n t vektory alebo body. Nechaj
X (l) - priemer vzorky cez body spadajúce do zhluku S f , alebo ťažisko klastra 5.. Potom sa rozlišujú tieto vzdialenosti medzi klastrami, ktoré vo vnútri nemajú iné zhluky:
1) vzdialenosť medzi klastrami podľa princípu „blízkeho suseda“.

2) vzdialenosť medzi klastrami podľa princípu „ďalekého suseda“

3) vzdialenosť medzi ťažiskami skupín
4) vzdialenosť medzi klastrami podľa princípu „priemerného spojenia“
5) zovšeobecnená Kolmogorovova vzdialenosť
Vzdialenosť medzi klastrami, ktoré sú spojením iných tried, možno vypočítať pomocou všeobecného vzorca:
Kde S^k^- zhluk získaný spojením tried Sk A S t .
Všetky špeciálne prípady vzdialeností sú získané z tohto všeobecného vzorca. Pri a = p = 1/2, 8 = -1/2, y = 0 máme vzdialenosť podľa princípu „blízkeho suseda“, pričom a = p = 5 = 1/2, y = O - „vzdialený sused“,
vo vzdialenosti \u003d ---, p \u003d---, 5 \u003d 0, y \u003d 0 - vzdialenosť pozdĺž ťažísk
p k + n i p k + n i
skupiny.
Metódy klastrovej analýzy sa delia na I) aglomeratívne (spájanie), II) deliace (separujúce) a III) iteračné.
Tí prví dôsledne spájajú jednotlivé objekty do zhlukov, tí druhí naopak zhluky rozdeľujú na objekty. Tretia kombinuje prvé dve. Ich vlastnosťou je vytváranie zhlukov na základe podmienok rozdelenia (tzv. parametrov), ktoré je možné počas prevádzky algoritmu meniť, aby sa zlepšila kvalita rozdelenia. Na klasifikáciu veľkého množstva informácií sa bežne používajú iteračné metódy.
Pozrime sa podrobnejšie na aglomeračné metódy. Aglomeratívne metódy sú najjednoduchšie a najbežnejšie medzi algoritmami klastrovej analýzy. V prvom kroku každý vektor alebo objekt X 19 ..., X s zdrojové údaje sa považujú za samostatný klaster alebo triedu. Podľa vypočítanej matice vzdialeností sa vyberú a kombinujú najbližšie k sebe. Je zrejmé, že proces sa skončí (P - 1) krok, kedy sa v dôsledku toho všetky objekty spoja do jedného zhluku.
Postupnosť asociácií môže byť reprezentovaná ako dendrogram alebo strom. Na obr. 1.18 ukazuje, že vektory boli v prvom kroku kombinované Xt, X2, pretože vzdialenosť medzi nimi je 0,3.
V druhom kroku sa k nim pripojil vektor X 3 ďaleko od klastra (X 1, X 2) do vzdialenosti 0,5 atď. V poslednom kroku sa všetky vektory spoja do jedného zhluku.

Ryža. 1.18.
Aglomeratívne metódy zahŕňajú metódy jednoduchého, priemerného, úplného spojenia a Wardovu metódu.
1.jediný spôsob pripojenia. Nechaj X v ..., X n - vektorové dáta, pričom každý vektor tvorí jeden zhluk. Najprv sa vypočíta matica vzdialeností medzi týmito klastrami a ako metrika sa použije vzdialenosť najbližšieho suseda. Pomocou tejto matice sa vyberú dva najbližšie vektory, ktoré tvoria prvý zhluk 5,. Ďalší krok medzi S] a zvyšných vektorov (ktoré považujeme za zhluky), vypočíta sa nová matica vzdialenosti a vzdialenosť medzi zhlukami sa spojí do tried (a = p = 1/2, 5 = -1/2, y = 0) sa používa ako metrika. Najbližšie k predchádzajúcej triede S( zhluk sa s ním spája, tvorí S2. Cez atď P- 1 krok, dostaneme, že všetky vektory sú spojené do jedného zhluku.
Výhody: 1) v každom kroku algoritmu sa pridáva iba jeden prvok, 2) metóda je extrémne jednoduchá, 3) algoritmus je necitlivý na transformácie počiatočných údajov (rotácia, posun, translácia, natiahnutie).
Nedostatky: 1) je potrebné neustále prepočítavať maticu vzdialeností, 2) počet zhlukov je vopred známy a nedá sa znížiť
Kde Komu -číslo klastra, ja- vektorové číslo v klastri, j- súradnicové číslo X t e U1 R, p do- počet vektorov v zhluku, Xjk- vzorový priemer X i V S k . Hodnota Vk charakterizuje odchýlky vektorov od seba v rámci klastra (nov Sk+Sf alebo starý^). Kalkulácia Vk by sa mali vykonávať pred a po zväzku, pričom je potrebné prejsť všetkými možnými variantmi takýchto zväzkov. Neskôr v klastri Sk pridajú sa len tie vektory alebo zhluky, ktorých výsledkom je najmenšia zmena Vk po zlúčení a v dôsledku toho sa bude nachádzať v minimálnej vzdialenosti od pôvodného zhluku S k .
Zvážte ďalšie iteračné metódy. Podstatou iteračných metód je, že zhlukovanie začína nastavením niektorých počiatočných podmienok. Napríklad je potrebné nastaviť počet zhlukov, ktoré sa majú získať, alebo nastaviť vzdialenosť, ktorá určuje koniec procesu tvorby zhlukov atď. Počiatočné podmienky sa volia podľa výsledku, ktorý výskumník potrebuje. Väčšinou sa však nastavujú podľa riešenia nájdeného niektorou z aglomeračných metód. Medzi iteračné metódy patrí metóda ^-priemerov a metóda hľadania koncentrácií.
1. Metóda /r-znamená. Nech sú vektory Xl9 ..., Xn e9F a je potrebné ich rozdeliť na Komu klastre. Na nultom kroku P vektory náhodne vyberte si Komu z nich za predpokladu, že každý tvorí jeden zhluk. Získame množinu referenčných zhlukov,...,e[ 0) s váhami
čoj 0),...,X. a vypočítajte maticu vzdialenosti medzi X. a normy e 1 (0),...,^ 0) podľa nejakej metriky, napríklad podľa euklidovskej:
Na základe znalosti vypočítanej matice vzdialenosti, vektora X ( je umiestnený v štandarde, ktorého vzdialenosť je minimálna. Predpokladajme pre istotu, čo to je. Nahrádza sa novým, prepočítaným s prihliadnutím na pripojený bod, podľa vzorca

Okrem toho sa hmotnosť prepočítava:

Ak sa v matici vyskytujú dve alebo viac minimálnych vzdialeností, potom X t zahrnuté v klastri s najnižším poradovým číslom.
V ďalšom kroku sa zo zostávajúcich vektorov vyberie ďalší vektor a postup sa zopakuje. Teda prostredníctvom ( PC) kroky ku každému
štandardné e^~ k) bude zodpovedať hmotnosti a postup zhlukovania sa ukončí. S veľkým P a malé Komu algoritmus rýchlo konverguje k stabilnému riešeniu, t. j. k riešeniu, v ktorom sa štandardy získané po prvej aplikácii algoritmu zhodujú v počte a zložení so štandardmi zistenými pri opakovaní metódy. Algoritmický postup sa však vždy niekoľkokrát opakuje, pričom sa ako referenčné vektory (ako počiatočná aproximácia) používa oblasť získaná v predchádzajúcich výpočtoch: predtým nájdené referencie e[ p k e (2 p k) k) braný za e (x 0) 9 ... 9 e (k 0) 9 a algoritmický postup sa opakuje.
osudové očakávaná hodnota X \u003d ~ Y] X 5. Potom stred gule
nosené v X a postup výpočtu sa zopakuje. Podmienkou ukončenia iteračného procesu je rovnosť stredných vektorov X našiel na T A (t+ 1) kroky. Prvky uväznené vo vnútri gule X 9 ... 9 X
zaradíme ich do jedného zhluku a vylúčime z ďalšieho výskumu. Pre zostávajúce body sa algoritmus opakuje. Algoritmus konverguje pre akúkoľvek voľbu počiatočnej aproximácie a akékoľvek množstvo počiatočných údajov. Avšak na získanie stabilného oddielu (t. j. oddielu, v ktorom sa zhluky nájdené po prvej aplikácii algoritmu zhodujú v počte a zložení so zhlukmi nájdenými pri opakovaní metódy), sa odporúča algoritmický postup niekoľkokrát zopakovať. pre rôzne hodnoty polomeru gule R. Znakom stabilného oddielu bude vytvorenie rovnakého počtu zhlukov s rovnakým zložením.
Všimnite si, že problém klastrovania nemá jedinečné riešenie. V dôsledku toho je pomerne ťažké a nie vždy možné vymenovať všetky prípustné delenia údajov do tried. Aby bolo možné posúdiť kvalitu rôznymi spôsobmi klastrovanie zavádza pojem funkcionálu kvality partície, ktorý má minimálnu hodnotu na najlepšej (z pohľadu výskumníka) partícii.
Nechaj X X9 ... 9 X p e U1 R - nejaký súbor pozorovaní, ktorý je rozdelený do tried S = (S19 ... 9 Sk) 9 a Komu vopred známy. Potom majú hlavné funkcie kvality rozdelenia pre známy počet klastrov tento tvar:
1) Vážený súčet vnútrotriednych rozptylov

Kde a(1)- selektívne matematické očakávanie zhluku S l
Funkčné Q((S) nám umožňuje odhadnúť stupeň homogenity všetkých zhlukov ako celku.
2) Súčet párových vzdialeností v rámci triedy medzi prvkami  alebo
alebo

Kde p 1- počet prvkov v zhluku S { .
3) Zovšeobecnený vnútrotriedny rozptyl

Kde nj- počet prvkov v S., A; . - vzorová kovariančná matica pre sj.
Funkcionál je aritmetický priemer zovšeobecnených vnútrotriednych rozptylov vypočítaných pre každý klaster. Ako je známe, zovšeobecnený rozptyl umožňuje odhadnúť stupeň rozptylu viacrozmerných pozorovaní. Preto 3. otázka (S) umožňuje odhadnúť priemerný rozptyl pozorovacích vektorov v triedach S l9 ... 9 S k . Odtiaľ pochádza jeho názov – zovšeobecnený vnútrotriedny rozptyl. 3. otázka (S) sa používa, keď je potrebné vyriešiť problém kompresie dát alebo koncentrácie pozorovaní v priestore s rozmerom menším ako bol pôvodný.
4) Kvalitu klasifikácie pozorovaní je možné posúdiť aj pomocou Hotellingovho kritéria. Na tento účel použijeme kritérium na testovanie hypotézy H 0 o rovnosti stredných vektorov dvoch viacrozmerných populácií a vypočítajte štatistiku
Kde n t A p t - počet vektorov v triedach Sl,Sm; X, Xt- vycentrované počiatočné údaje; S*- združená kovariančná matica zhlukov S n S m: S* =--- (XjX l + X^X m). Ako predtým, hodnota Q 4 (S)
p,+p t-2
v porovnaní s tabuľkovou hodnotou vypočítanou podľa vzorca
Kde m- počiatočný rozmer pozorovacích vektorov a je hladinou významnosti.
Hypotéza H 0 je akceptovaná s pravdepodobnosťou (1-oc), ak Q4(S)n_m, a je odmietnutý inak.
Kvalitu rozdelenia do tried je možné odhadnúť aj empiricky. Napríklad je možné porovnať priemer vzorky nájdený pre každú triedu s priemerom vzorky celej populácie pozorovaní. Ak sa líšia o faktor dva alebo viac, potom je rozdelenie dobré. Správnejšie porovnanie priemerov zhlukovej vzorky s priemernou vzorkou celej populácie pozorovaní vedie k použitiu analýza rozptylu hodnotiť kvalitu rozdelenia do tried.
Ak počet zhlukov v S = (Sl9 ...,Sk) nie je vopred známy, potom sa pre ľubovoľne zvolené celé číslo použijú nasledujúce funkcionály kvality rozdelenia m:
jajaKomu 1 1 m
- - priemerná miera vnútrotriedy
P i=1 n i XjeSj X"tSj J
rozhadzovanie sovy,
P nV l J J
S, - počet prvkov v zhluku obsahujúcom bod X g
Všimnite si, že pre ľubovoľnú hodnotu parametra T funkčné Z m (S) dosiahne minimum rovné I/p, ak pôvodné zhlukovanie S = (Sl9 ...,Sk) je rozdelenie do monoklastrov S. = (Xj), pretože V(Xt) = 1. V rovnakom čase Zm (S) dosiahne maximálne 1 ak S- jeden klaster obsahujúci všetky počiatočné údaje,
pretože V(X() = n. V konkrétnych prípadoch sa to dá ukázať Z_l(S)=-, Kde Komu - počet rôznych zhlukov v S = (Si9...9Sk)9ZX(S)= max - ,
*"V P)
Kde n t - počet prvkov v klastri S i9 Z^(S) = min - ,
G" P)
Všimnite si, že v prípade neznámeho počtu klastrov funguje kvalita rozdelenia Q(S) možno zvoliť ako algebraickú kombináciu (súčet, rozdiel, súčin, pomer) dvoch funkcionalít I m (S), Z m (S), keďže prvá je klesajúca a druhá rastúca funkcia počtu tried Komu. Takéto správanie Z m (S)
garantuje existenciu extrému Q(S).
Úvod
Pojem klastrová analýza, ktorý prvýkrát zaviedol Tryon v roku 1939, zahŕňa viac ako 100 rôznych algoritmov.
Na rozdiel od klasifikačných problémov, klastrová analýza nevyžaduje a priori predpoklady o súbore údajov, neukladá obmedzenia na reprezentáciu skúmaných objektov a umožňuje analyzovať ukazovatele rôznych typov údajov (intervalové údaje, frekvencie, binárne údaje) . Treba mať na pamäti, že premenné sa musia merať na porovnateľných mierkach.
Klastrová analýza vám umožňuje zmenšiť rozmer údajov a urobiť ich vizuálnymi.
Zhlukovú analýzu možno aplikovať na množiny časových radov, tu možno rozlíšiť obdobia podobnosti niektorých ukazovateľov a určiť skupiny časových radov s podobnou dynamikou.
Zhluková analýza sa vyvíjala paralelne v niekoľkých smeroch, ako je biológia, psychológia a iné, takže väčšina metód má dva alebo viac názvov.
Úlohy klastrovej analýzy možno zoskupiť do nasledujúcich skupín:
Vypracovanie typológie alebo klasifikácie.
Skúmanie užitočných koncepčných schém na zoskupovanie objektov.
Prezentácia hypotéz založených na prieskume údajov.
Testovanie hypotéz alebo výskum s cieľom zistiť, či typy (skupiny) identifikované tak či onak sú skutočne prítomné v dostupných údajoch.
Pri praktickom použití zhlukovej analýzy sa spravidla rieši niekoľko z týchto úloh súčasne.
Účel lekcie
Získanie zručností v praktickej aplikácii hierarchických a iteračných metód zhlukovej analýzy.
Praktická úloha
Vyvinúť algoritmy pre metódy blízkeho suseda a k-stredné a realizovať ich vo forme počítačových programov. Vytvorte 50 implementácií pomocou DNC X= (X 1 ,X 2) - náhodná 2-rozmerná premenná, ktorej súradnice sú rovnomerne rozložené v intervale (3.8). Rozdeľte ich pomocou vyvinutých programov do minimálneho počtu zhlukov, z ktorých každý je umiestnený v guli s polomerom 0,15.
Smernice
Názov klastrová analýza pochádza z anglického slova cluster - parta, akumulácia Cluster analysis je široká trieda mnohorozmerných štatistických analytických postupov, ktoré umožňujú automatizované zoskupovanie pozorovaní do homogénnych tried - zhlukov.
Klaster má nasledujúce matematické charakteristiky:
klastrová disperzia;
smerodajná odchýlka.
Stred klastra je miestom bodov v priestore premenných.
Polomer klastra - maximálna vzdialenosť bodov od stredu zhluku.
Disperzia zhlukov je mierou šírenia bodov v priestore vzhľadom k stredu zhluku.
Smerodajná odchýlka (RMS) objektov vo vzťahu k stredu klastra je druhá odmocnina z rozptylu klastra.
Metódy klastrovej analýzy
Metódy klastrovej analýzy možno rozdeliť do dvoch skupín:
hierarchický;
nehierarchické.
Každá skupina obsahuje mnoho prístupov a algoritmov.
Pomocou rôznych metód zhlukovej analýzy môže analytik získať rôzne riešenia na rovnakých údajoch. Toto sa považuje za normálne.
Hierarchické metódy zhlukovej analýzy
Podstatou hierarchického zhluku je postupné spájanie menších zhlukov do väčších zhlukov alebo delenie veľkých zhlukov na menšie.
Hierarchické aglomeratívne metódy(Aglomeratívne hniezdenie, AGNES)
Táto skupina metód sa vyznačuje konzistentnou kombináciou počiatočných prvkov a zodpovedajúcim poklesom počtu zhlukov.
Na začiatku algoritmu sú všetky objekty samostatné zhluky. V prvom kroku sa najpodobnejšie objekty spoja do zhluku. V nasledujúcich krokoch zlučovanie pokračuje, kým všetky objekty nevytvoria jeden zhluk.
Hierarchické deliteľné (deliteľné) metódy(DIVIZÍVNA ANALÝZA, DIANA)
Tieto metódy sú logickým opakom aglomeračných metód. Na začiatku algoritmu patria všetky objekty do jedného zhluku, ktorý sa v nasledujúcich krokoch rozdelí na menšie zhluky, čím sa vytvorí postupnosť deliacich skupín.
Hierarchické metódy klastrovania sa líšia v pravidlách vytvárania zhlukov. Pravidlá sú kritériá, ktoré sa používajú pri rozhodovaní o „podobnosti“ objektov, keď sú spojené do skupiny.
Miery podobnosti
Na výpočet vzdialenosti medzi objektmi sa používajú rôzne miery podobnosti (miery podobnosti), nazývané aj metriky alebo funkcie vzdialenosti.
Euklidovská vzdialenosť je geometrická vzdialenosť vo viacrozmernom priestore a vypočíta sa podľa vzorca (4.1).
Euklidovská vzdialenosť (a jej druhá mocnina) sa vypočítava z pôvodných údajov, nie zo štandardizovaných údajov.
Euklidovská vzdialenosť na druhú sa vypočíta podľa vzorca (4.2).
 (4.2)
(4.2)
Vzdialenosť Manhattan (vzdialenosť mestských blokov), tiež nazývaná vzdialenosť „hamming“ alebo „mestský blok“, sa vypočíta ako priemer rozdielov medzi súradnicami. Vo väčšine prípadov táto miera vzdialenosti vedie k výsledkom podobným výpočtom euklidovskej vzdialenosti. Pre toto opatrenie je však vplyv jednotlivých odľahlých hodnôt menší ako pri použití euklidovskej vzdialenosti, pretože tu nie sú súradnice odmocnené. Vzdialenosť Manhattan sa vypočíta pomocou vzorca (4.3).
 (4.3)
(4.3)
Čebyševova vzdialenosť by sa mal použiť, keď je potrebné definovať dva objekty ako "odlišné", ak sa líšia v jednom rozmere. Čebyševova vzdialenosť sa vypočíta podľa vzorca (4.4).
 (4.4)
(4.4)
Výkonová vzdialenosť sa používa, keď sa chce postupne zvyšovať alebo znižovať hmotnosť týkajúcu sa rozmeru, pre ktorý sú zodpovedajúce predmety veľmi odlišné. Výkonová vzdialenosť sa vypočíta podľa vzorca (4.5).
 (4.5)
(4.5)
Kde r A p- užívateľom definované parametre. Parameter p je zodpovedný za postupné váženie rozdielov nad jednotlivými súradnicami, parametrom r na progresívne váženie veľkých vzdialeností medzi objektmi. Ak obe možnosti r A p sa rovnajú dvom, potom sa táto vzdialenosť zhoduje s Euklidovou vzdialenosťou.
Percento nesúhlasu používa sa, keď sú údaje kategorické. Táto vzdialenosť sa vypočíta podľa vzorca (4.6).
 (4.6)
(4.6)
Metódy pripojenia alebo prepojenia
V prvom kroku, keď je každý objekt samostatným zhlukom, sú vzdialenosti medzi týmito objektmi určené vybranou mierou. Ak je však viacero objektov navzájom prepojených, na určenie vzdialenosti medzi klastrami sa musia použiť iné metódy. Existuje mnoho spôsobov spájania klastrov:
Single link (metóda najbližšieho suseda) – vzdialenosť medzi dvoma zhlukmi je určená vzdialenosťou medzi dvoma najbližšími objektmi (najbližšími susedmi) v rôznych zhlukoch.
Úplné spojenie (metóda najvzdialenejších susedov) – vzdialenosti medzi zhlukami sú určené najväčšou vzdialenosťou medzi akýmikoľvek dvoma objektmi v rôznych zhlukoch (t. j. „najvzdialenejší susedia“).
Nevážený párový priemer - vzdialenosť medzi dvoma rôznymi zhlukami sa vypočíta ako priemerná vzdialenosť medzi všetkými pármi objektov v nich.
Vážený párový priemer – metóda je totožná s metódou nevážený párový priemer, okrem toho, že veľkosť zodpovedajúcich zhlukov (t. j. počet objektov, ktoré obsahujú) sa pri výpočtoch používa ako váhový faktor.
Metóda neváženého ťažiska - vzdialenosť medzi dvoma zhlukami je definovaná ako vzdialenosť medzi ich ťažiskami.
Metóda váženého ťažiska (medián) - metóda je identická s metódou neváženého ťažiska s tým rozdielom, že pri výpočtoch sa používajú váhy, ktoré zohľadňujú rozdiel medzi veľkosťami zhlukov (t. j. počtom objektov v nich).
Wardova metóda - vzdialenosť medzi zhlukami je definovaná ako zväčšenie súčtu štvorcových vzdialeností objektov k stredom zhlukov, získané ako výsledok ich spojenia. Metóda sa líši od všetkých ostatných metód, pretože používa metódy ANOVA na odhad vzdialeností medzi klastrami. Metóda minimalizuje súčet štvorcov pre akékoľvek dva (hypotetické) zhluky, ktoré môžu byť vytvorené v každom kroku.
Metóda najbližšieho suseda
Vzdialenosť medzi dvoma triedami je definovaná ako vzdialenosť medzi ich najbližšími členmi.
Pred spustením algoritmu sa vypočíta matica vzdialenosti medzi objektmi. Podľa klasifikačného kritéria dochádza k spojeniu medzi zhlukmi, ktorých vzdialenosť medzi najbližšími zástupcami je najmenšia: vyberú sa dva objekty s najmenšou vzdialenosťou do jedného zhluku. Potom je potrebné prepočítať maticu vzdialenosti s prihliadnutím na nový zhluk. V každom kroku sa v matici vzdialenosti hľadá minimálna hodnota zodpovedajúca vzdialenosti medzi dvoma najbližšími klastrami. Nájdené zhluky sa spoja a vytvoria nový zhluk. Tento postup sa opakuje, kým sa nezlúčia všetky klastre.
Pri použití metódy najbližšieho suseda je potrebné venovať osobitnú pozornosť výberu vzdialenosti medzi objektmi. Na jej základe sa vytvorí matica počiatočnej vzdialenosti, ktorá určuje celý ďalší proces klasifikácie.
iteračné metódy.
Pri veľkom počte pozorovaní nie sú vhodné hierarchické metódy zhlukovej analýzy. V takýchto prípadoch sa používajú nehierarchické metódy založené na rozdelení pôvodných zhlukov do iných zhlukov, ktoré sú iteračnými metódami na rozdelenie pôvodnej populácie. Počas procesu delenia sa vytvárajú nové zhluky, kým nie je splnené pravidlo zastavenia.
Takéto nehierarchické zhlukovanie pozostáva z rozdelenia súboru údajov do určitého počtu odlišných zhlukov. Sú dva prístupy. Prvým je definovanie hraníc zhlukov ako najhustejších oblastí vo viacrozmernom priestore pôvodných údajov, t. j. definícia zhluku, kde je veľký „bodový zhluk“. Druhým prístupom je minimalizovať mieru rozdielu objektov.
Na rozdiel od metód hierarchickej klasifikácie môžu iteračné metódy viesť k vytvoreniu prekrývajúcich sa zhlukov, kedy jeden objekt môže súčasne patriť do viacerých zhlukov.
Medzi iteratívne metódy patrí napríklad metóda k-priemery, spôsob hľadania koncentrácií a iné. Iteračné metódy sú rýchle, čo umožňuje ich použitie na spracovanie veľkých polí počiatočných informácií.
Algoritmus k-means (k-means)
Spomedzi iteračných metód je najobľúbenejšou metódou metóda k- priemerný McKean. Na rozdiel od hierarchických metód musí vo väčšine implementácií tejto metódy používateľ sám špecifikovať požadovaný počet finálnych zhlukov, ktorý sa zvyčajne označuje ako „ k". Algoritmus k- stredné stavby k zhluky umiestnené čo najďalej od seba. Hlavná požiadavka na typ problémov, ktoré algoritmus rieši k-priemery - prítomnosť predpokladov (hypotéz) ohľadom počtu zhlukov, pričom by sa mali čo najviac líšiť. Výber čísla k môžu byť založené na predchádzajúcom výskume, teoretických úvahách alebo intuícii.
Rovnako ako v hierarchických metódach klastrovania si používateľ môže vybrať jeden alebo druhý typ miery podobnosti. Algoritmy rôznych metód k-priemery sa líšia aj spôsobom výberu počiatočných centier daných zhlukov. V niektorých verziách metódy môže (alebo musí) používateľ sám určiť takéto počiatočné body, a to buď ich výberom z reálnych pozorovaní, alebo zadaním súradníc týchto bodov pre každú z premenných. V iných implementáciách tejto metódy výber daného čísla k počiatočné body sa vytvárajú náhodne a tieto počiatočné body (centrá klastrov) možno následne spresniť v niekoľkých fázach. Existujú 4 hlavné fázy takýchto metód:
zvolený alebo ustanovený k pozorovania, ktoré budú primárnymi centrami klastrov;
ak je to potrebné, stredné zhluky sa vytvoria priradením každého pozorovania k najbližším špecifikovaným stredom zhlukov;
po priradení všetkých pozorovaní k jednotlivým zhlukom sú primárne centrá zhlukov nahradené priemermi zhlukov;
predchádzajúca iterácia sa opakuje, kým sa zmeny v súradniciach stredov klastrov nestanú minimálnymi.
Všeobecná myšlienka algoritmu: daný pevný počet k pozorovacích klastrov sa porovnáva so klastrami tak, aby sa priemery v klastri (pre všetky premenné) od seba čo najviac líšili.
Popis algoritmu
Počiatočná distribúcia objektov podľa zhlukov.
Vybrané číslo k A k bodov. V prvom kroku sa tieto body považujú za „stredy“ zhlukov. Každý zhluk zodpovedá jednému centru. Výber počiatočných ťažísk sa môže uskutočniť takto:
výber k- pozorovania na maximalizáciu počiatočnej vzdialenosti;
náhodný výber k- pozorovania;
prvá voľba k- pozorovania.
Každý objekt je potom priradený k určitému najbližšiemu zhluku.
Iteračný proces.
Vypočítajú sa stredy zhlukov, ktoré sa potom a ďalej považujú za súradnicové prostriedky zhlukov. Objekty sa opäť prerozdelia. Proces výpočtu stredísk a prerozdeľovania objektov pokračuje, kým nie je splnená jedna z nasledujúcich podmienok:
klastrové centrá sa stabilizovali, t.j. všetky pozorovania patria do klastra, do ktorého patrili pred aktuálnou iteráciou. V niektorých verziách tejto metódy môže používateľ nastaviť číselnú hodnotu kritéria, ktorá sa interpretuje ako minimálna vzdialenosť pre výber nových stredov klastra. Pozorovanie sa nebude považovať za kandidáta na nové centrum klastra, ak jeho vzdialenosť od nahradeného centra klastra presiahne špecifikovaný počet. Takýto parameter sa v mnohých programoch nazýva "polomer". Okrem tohto parametra je možné nastaviť zvyčajne dostatočne malé číslo, s ktorým sa porovnáva zmena vzdialenosti pre všetky stredy klastra. Tento parameter sa zvyčajne nazýva "konvergencia", pretože odráža konvergenciu procesu iteratívneho klastrovania;
počet iterácií sa rovná maximálnemu počtu iterácií.
Kontrola kvality klastrovania
Po získaní výsledkov zhlukovej analýzy metódou k- priemery, mali by ste skontrolovať správnosť zhlukovania (t.j. zhodnotiť, ako sa zhluky navzájom líšia). Na tento účel sa vypočítajú priemerné hodnoty pre každý klaster. Dobré zhlukovanie by malo produkovať veľmi odlišné prostriedky pre všetky merania, alebo aspoň pre väčšinu z nich.
Výhodyalgoritmus k-means:
jednoduchosť použitia;
rýchlosť používania;
jasnosť a transparentnosť algoritmu.
Nedostatkyalgoritmus k-means:
Algoritmus je príliš citlivý na odľahlé hodnoty, ktoré môžu skresliť priemer. Možným riešením tohto problému je použitie modifikácie algoritmu - algoritmu k- mediány;
Algoritmus môže byť pomalý vo veľkých databázach. Možným riešením tohto problému je použitie vzorkovania údajov.
Správa musí obsahovať:
popis a blokové schémy algoritmov;
zdrojové texty programových modulov;
výsledky algoritmov vo forme grafov.
1.1. Hierarchické aglomeratívne (kombinačné) metódy sú metódy, ktoré sekvenčne spájajú objekty do zhlukov. V prvom kroku sa každý vzorový objekt považuje za samostatný zhluk; ďalej sa na základe matice podobnosti kombinujú objekty najbližšie k sebe. Podobne je každý objekt buď zoskupený s iným objektom, alebo zahrnutý do existujúceho klastra. Proces zhlukovania je konečný a pokračuje, kým sa všetky objekty neskombinujú do jedného zhluku. Samozrejme, takýto výsledok vo všeobecnom prípade nedáva zmysel a výskumník nezávisle určuje, v ktorom bode by sa malo zhlukovanie ukončiť.
1.2. Hierarchické deliace (separačné) metódy sú metódy, ktoré postupne rozdeľujú skupiny na samostatné objekty. Hlavným predpokladom metód je, že spočiatku všetky objekty patria do rovnakého klastra. V procese zhlukovania sa podľa určitých pravidiel z tohto zhluku oddeľujú skupiny navzájom podobných objektov. V každej fáze sa teda počet zhlukov zvyšuje.
Treba poznamenať, že aglomeratívne aj deliace metódy môžu byť implementované pomocou rôznych algoritmov.
2. Iteračné metódy- podstata metód spočíva v tom, že proces klasifikácie začína určením počiatočných podmienok pre zhlukovanie (počet vytvorených zhlukov, súradnice stredov počiatočných zhlukov atď.). Zmena počiatočných podmienok výrazne mení výsledky zhlukovania, takže použitie týchto metód si vyžaduje predbežné štúdium všeobecnej populácie, najmä pomocou hierarchických metód zhlukovej analýzy. Najčastejšie sa po hierarchických metódach používajú iteračné metódy. Iteračné metódy môžu viesť k vytvoreniu prekrývajúcich sa zhlukov, kedy jeden objekt patrí do viacerých zhlukov súčasne.
Medzi iteračné metódy patrí: metóda Komu-priemery, spôsob hľadania koncentrácií a pod.
Pri výbere metód klastrovej analýzy sa riadia predchádzajúcimi skúsenosťami, dostupnými informáciami o všeobecnej populácii a počiatočnými údajmi. Treba poznamenať, že na počiatočná fáza, najčastejšie sa volí niekoľko metód klastrovej analýzy naraz, čo vedie k rôznym výsledkom klastrovania. Získané klasifikácie objektov sú analyzované pomocou kvalitatívnych kritérií, ktoré vám umožňujú vybrať si najkvalitnejšiu klasifikáciu.
Pre veľké populácie sú všetky metódy zhlukovej analýzy veľmi časovo náročné, preto sa v súčasnej fáze ich aplikácia realizuje pomocou softvérové produkty, najmä program SPSS.
Dosť podrobný prehľad a systematizácia rôzne metódy zhluková analýza je uvedená v .
Základom hierarchických metód zhlukovej analýzy je definícia miery podobnosti objekty podľa pozorovateľných premenných. Na kvantifikáciu podobnosti v zhlukovej analýze sa zavádza pojem metriky. Podobnosť alebo rozdiel medzi objektmi sa určuje v závislosti od metrickej vzdialenosti medzi objektmi. Existujú rôzne miery podobnosti medzi objektmi, medzi nimi sú najobľúbenejšie:
Euklidovská vzdialenosť medzi objektmi:
vážená euklidovská vzdialenosť:
Vzdialenosť medzi i A j predmety,
Význam Komu-tá premenná y i- predmet,
Význam do- y premenná j- predmet,
týždeň- pridelenú váhu do- premennej.
Ak sú objekty opísané nemetrickými premennými, potom možno ako miery podobnosti použiť koeficienty poradovej korelácie (napríklad Pearsonove párové korelačné koeficienty), koeficienty asociatívnosti a iné miery podobnosti.
Pri veľkom počte pozorovaní nie sú vhodné hierarchické metódy zhlukovej analýzy. V takýchto prípadoch sa používajú nehierarchické metódy založené na delení, čo sú iteratívne metódy rozdelenia pôvodnej populácie. Počas procesu delenia sa vytvárajú nové zhluky, kým nie je splnené pravidlo zastavenia.
Takéto nehierarchické zhlukovanie pozostáva z rozdelenia súboru údajov do určitého počtu odlišných zhlukov. Sú dva prístupy. Prvým je definovanie hraníc zhlukov ako najhustejších oblastí vo viacrozmernom priestore počiatočných údajov, t.j. definícia zhluku, kde je veľká „koncentrácia bodov“. Druhým prístupom je minimalizovať mieru rozdielu objektov
Algoritmus k-means (k-means)
Najbežnejším medzi nehierarchickými metódami je algoritmus k-means, nazývaný aj rýchla klastrová analýza. Kompletný popis algoritmu možno nájsť v Hartigan a Wong (1978). Na rozdiel od hierarchických metód, ktoré nevyžadujú predbežné predpoklady o počte zhlukov, aby bolo možné túto metódu použiť, je potrebné mať hypotézu o najpravdepodobnejšom počte zhlukov.
Algoritmus k-means vytvára k zhlukov rozmiestnených čo najďalej od seba. Hlavným typom problémov, ktoré algoritmus k-means rieši, je prítomnosť predpokladov (hypotéz) o počte zhlukov, pričom by sa mali čo najviac líšiť. Voľba čísla k môže byť založená na predchádzajúcom výskume, teoretických úvahách alebo intuícii.
Všeobecná myšlienka algoritmu: daný pevný počet k pozorovacích klastrov sa porovnáva so klastrami tak, aby sa priemery v klastri (pre všetky premenné) od seba čo najviac líšili.
Popis algoritmu
Obrázok 1 - Príklad fungovania algoritmu k-means (k=2)
Výber počtu klastrov je zložitá otázka. Ak neexistujú žiadne predpoklady o tomto čísle, odporúča sa vytvoriť 2 klastre, potom 3, 4, 5 atď., pričom sa porovnávajú výsledky.
Kontrola kvality klastrovania
Po získaní výsledkov zhlukovej analýzy metódou k-means by sa mala skontrolovať správnosť zhlukovania (t. j. zhodnotiť, ako sa zhluky navzájom líšia). Na tento účel sa vypočítajú priemerné hodnoty pre každý klaster. Dobré zhlukovanie by malo produkovať veľmi odlišné prostriedky pre všetky merania, alebo aspoň pre väčšinu z nich.
Výhody algoritmu k-means:
PAM je modifikáciou algoritmu k-means, k-mediánového algoritmu (k-medoidov).
Algoritmus je menej citlivý na dátový šum a odľahlé hodnoty ako algoritmus k-means, pretože medián je menej ovplyvnený odľahlými hodnotami.
PAM je účinný pre malé databázy, ale nemal by sa používať pre veľké súbory údajov. Predzmenšenie rozmerov
Zvážte príklad. Existuje databáza klientov spoločnosti, ktorá by mala byť rozdelená do homogénnych skupín. Každý klient je opísaný pomocou 25 premenných. Použitie takého veľkého počtu premenných vedie k výberu zhlukov fuzzy štruktúry. V dôsledku toho je pre analytika pomerne ťažké interpretovať výsledné zhluky.
Zrozumiteľnejšie a transparentnejšie výsledky zhlukovania možno získať, ak sa namiesto súboru počiatočných premenných použijú niektoré zovšeobecnené premenné alebo kritériá, ktoré obsahujú informácie o vzťahoch medzi premennými v komprimovanej forme. Tie. vzniká problém redukcie rozmerov údajov. Dá sa vyriešiť rôznymi metódami; jednou z najbežnejších je faktorová analýza. Pozrime sa na to podrobnejšie.
Faktorová analýza
Faktorová analýza je technika používaná na štúdium vzťahov medzi hodnotami premenných.
Faktorová analýza má vo všeobecnosti dva ciele:
Kritériá alebo hlavné faktory identifikované ako výsledok faktorovej analýzy obsahujú informácie v komprimovanej forme o existujúcich vzťahoch medzi premennými. Tieto informácie vám umožňujú získať lepšie výsledky zhlukovania a lepšie vysvetliť sémantiku zhlukov. Faktory samotné môžu mať určitý význam.
Pomocou faktorovej analýzy sa veľké množstvo premenných redukuje na menší počet nezávislých ovplyvňujúcich veličín, ktoré sa nazývajú faktory.
Faktor v „komprimovanej“ forme obsahuje informácie o niekoľkých premenných. Premenné, ktoré medzi sebou vysoko korelujú, sa spájajú do jedného faktora. V dôsledku faktorovej analýzy sa zistia také komplexné faktory, ktoré čo najúplnejšie vysvetľujú vzťahy medzi uvažovanými premennými.
V prvom kroku faktorovej analýzy sú štandardizované hodnoty premenných, ktorých potreba bola uvažovaná v predchádzajúcej prednáške.
Faktorová analýza je založená na hypotéze, že analyzované premenné sú nepriamym prejavom relatívne malého počtu nejakých skrytých faktorov.
Faktorová analýza je súbor metód zameraných na identifikáciu a analýzu skrytých závislostí medzi pozorovanými premennými. Latentné závislosti sa tiež nazývajú latentné závislosti.
Jedna z metód faktorovej analýzy – metóda hlavných komponentov – je založená na predpoklade, že faktory sú na sebe nezávislé.
Iteratívne klastrovanie v SPSS Zvyčajne sa v štatistických balíkoch implementuje široký arzenál metód, čo umožňuje najprv zmenšiť rozmer súboru údajov (napríklad pomocou faktorovej analýzy) a potom samotné zhlukovanie (napríklad pomocou metódy rýchlej zhlukovej analýzy) . Zvážte túto možnosť pre klastrovanie v balíku SPSS.
Na zmenšenie rozmeru počiatočných údajov používame faktorová analýza. Ak to chcete urobiť, v ponuke vyberte: Analyzovať (Analýza) / Redukcia údajov (Transformácia údajov) / Faktor (Analýza faktorov):
Pomocou tlačidla Extrakcia: vyberte metódu extrakcie. Ponecháme predvolenú analýzu hlavných komponentov uvedenú vyššie. Zvoliť by ste si mali aj metódu rotácie – vyberme si jednu z najobľúbenejších – metódu varimax. Ak chcete uložiť hodnoty faktorov ako premenné, na karte „Hodnoty“ musí byť začiarknuté políčko „Uložiť ako premenné“.
Výsledkom tohto postupu je, že používateľ dostane správu "Vysvetlený celkový rozptyl", ktorý zobrazuje počet vybraných faktorov - to sú komponenty, ktorých vlastné hodnoty presahujú jednu.
Získané hodnoty faktorov, ktoré sú zvyčajne pomenované fakt1_1, fakt1_2 atď., sa používajú na zhlukovú analýzu metódou k-means. Ak chcete vykonať rýchlu analýzu klastrov, vyberte z ponuky:
Analyze/Classify/K-Means Cluster: (K-means cluster analysis).
V dialógovom okne K Means Cluster Analysis (Cluster analysis by k-means) musíte zadať faktorové premenné fact1_1, fact1_2 atď. v oblasti testovaných premenných. Tu je tiež potrebné zadať počet klastrov a počet iterácií.
V dôsledku tohto postupu získame správu s výstupom hodnôt stredov vytvorených zhlukov, počtu pozorovaní v každom zhluku, ako aj Ďalšie informácie, nastavené používateľom.
Algoritmus k-means teda rozdeľuje množinu počiatočných údajov do daného počtu zhlukov. Aby bolo možné vizualizovať získané výsledky, mal by sa použiť jeden z grafov, napríklad bodový graf. Tradičná vizualizácia je však možná pre obmedzený počet dimenzií, pretože, ako viete, človek môže vnímať iba trojrozmerný priestor. Ak teda analyzujeme viac ako tri premenné, mali by sme na prezentáciu informácií použiť špeciálne multidimenzionálne metódy, o ktorých bude reč v niektorej z nasledujúcich prednášok kurzu.
Metódy iteračného klastrovania sa líšia výberom nasledujúcich parametrov:
Napríklad v balíku SPSS, ak potrebujete pracovať s kvantitatívnymi (napríklad príjem) aj kategorickými (napríklad Rodinný stav) premenné a ak je množstvo údajov dostatočne veľké, použije sa metóda dvojstupňovej klastrovej analýzy, čo je škálovateľný postup klastrovej analýzy, ktorý umožňuje pracovať s údajmi rôznych typov. Na tento účel sa v prvej fáze práce záznamy vopred zoskupia do veľkého počtu podskupín. V druhej fáze sa výsledné podskupiny zoskupia do požadovaného počtu. Ak toto číslo nie je známe, postup ho automaticky určí. Týmto postupom môže pracovník banky napríklad selektovať skupiny ľudí, pričom súčasne využíva ukazovatele ako vek, pohlavie a úroveň príjmu. Získané výsledky umožňujú identifikovať klientov, ktorým hrozí nesplácanie úveru.
Vo všeobecnosti sú všetky fázy klastrovej analýzy prepojené a rozhodnutia prijaté v jednej z nich určujú akcie v nasledujúcich fázach.
Analytik sa musí rozhodnúť, či použije všetky pozorovania alebo vylúči niektoré údaje alebo vzorky zo súboru údajov.
Výber metriky a metódy štandardizácie počiatočných údajov.
Určenie počtu klastrov (pre iteračnú klastrovú analýzu).
Definovanie metódy klastrovania (pravidlá spájania alebo spájania).
Podľa mnohých odborníkov je pri určovaní formy a špecifickosti zhlukov rozhodujúci výber metódy klastrovania.
Analýza výsledkov zhlukovania. Táto fáza zahŕňa riešenie nasledujúcich otázok: je výsledné zhlukovanie náhodné; či je oddiel spoľahlivý a stabilný na čiastkových vzorkách údajov; či existuje vzťah medzi výsledkami klastrovania a premennými, ktoré sa nezúčastnili procesu klastrovania; či je možné interpretovať výsledky zhlukovania.
Kontrola výsledkov klastrovania. Výsledky klastrovania by mali byť overené aj formálnymi a neformálne metódy. Formálne metódy závisia od metódy použitej na zhlukovanie. Neformálne zahŕňajú nasledujúce postupy na kontrolu kvality klastrovania:
Ťažkosti a problémy, ktoré môžu vzniknúť pri aplikácii zhlukovej analýzy
Ako každá iná metóda, aj metódy klastrovej analýzy majú isté slabé stránky, t.j. určité ťažkosti, problémy a obmedzenia.
Pri vykonávaní klastrovej analýzy by sa malo vziať do úvahy, že výsledky klastrovania závisia od kritérií na rozdelenie súboru počiatočných údajov. Pri zmenšení dátovej dimenzie môže dochádzať k určitým skresleniam, v dôsledku zovšeobecňovania môže dôjsť k strate niektorých individuálnych charakteristík objektov.
Pred zhlukovaním je potrebné zvážiť množstvo zložitostí.
Pred klastrovaním môže mať analytik otázku, ktorú skupinu metód klastrovej analýzy uprednostniť. Pri výbere medzi hierarchickými a nehierarchickými metódami je potrebné vziať do úvahy nasledujúce vlastnosti.
Nehierarchické metódy odhaľujú vyššiu odolnosť voči šumu a odľahlým hodnotám, nesprávny výber metriky, zahrnutie nevýznamných premenných do súboru zapojených do zhlukovania. Cena, ktorú treba zaplatiť za tieto výhody metódy, je slovo „a priori“. Analytik musí vopred určiť počet klastrov, počet iterácií alebo pravidlo zastavenia, ako aj niektoré ďalšie parametre klastrovania. To je obzvlášť ťažké pre začiatočníkov.
Ak neexistujú žiadne predpoklady o počte zhlukov, odporúča sa použiť hierarchické algoritmy. Ak to však veľkosť vzorky neumožňuje, možná cesta- vykonanie série experimentov s rôznym počtom klastrov, napríklad začať s rozdelením súboru údajov z dvoch skupín a postupným zvyšovaním ich počtu porovnávať výsledky. Vďaka tejto "variácii" výsledkov sa dosiahne dostatočne veľká flexibilita zhlukovania.
Hierarchické metódy na rozdiel od nehierarchických odmietajú určiť počet zhlukov, ale budujú kompletný strom vnorených zhlukov.
Zložitosti metód hierarchického zhlukovania: obmedzenie objemu súboru údajov; výber miery blízkosti; nepružnosť získaných klasifikácií.
Výhodou tejto skupiny metód v porovnaní s nehierarchickými metódami je ich prehľadnosť a možnosť získať detailnú predstavu o štruktúre dát.
Pri použití hierarchických metód je možné pomerne jednoducho identifikovať odľahlé hodnoty v súbore údajov a v dôsledku toho zlepšiť kvalitu údajov. Tento postup je základom dvojkrokového klastrovacieho algoritmu. Takýto súbor údajov možno neskôr použiť na nehierarchické zhlukovanie.
Je tu ešte jeden aspekt, ktorý už bol spomenutý v tejto prednáške. Ide o zhlukovanie celej populácie údajov alebo ich vzorky. Tento aspekt je podstatný pre obe uvažované skupiny metód, ale kritickejší je pre hierarchické metódy. Hierarchické metódy nedokážu pracovať s veľkými súbormi údajov a použitie nejakého výberu, t.j. časť údajov by mohla umožniť použitie týchto metód.
Výsledky zoskupovania nemusia mať dostatočné štatistické opodstatnenie. Na druhej strane pri riešení klastrovacích problémov je akceptovateľná neštatistická interpretácia získaných výsledkov, ako aj pomerne široká škála možností koncepcie klastra. Takáto neštatistická interpretácia umožňuje analytikovi získať uspokojivé výsledky zhlukovania, čo je často ťažké pri použití iných metód.
Nové algoritmy a niektoré modifikácie algoritmov klastrovej analýzy
Metódy, o ktorých sme uvažovali v tejto a predchádzajúcich prednáškach, sú „klasikou“ zhlukovej analýzy. Až donedávna bola hlavným kritériom, podľa ktorého sa hodnotil klastrovací algoritmus, kvalita klastrovania: predpokladalo sa, že celý súbor údajov sa zmestí do pamäte RAM.
Avšak teraz, kvôli nástupu super veľkých databáz, existujú nové požiadavky, ktoré musí klastrovací algoritmus spĺňať. Hlavným, ako už bolo spomenuté v predchádzajúcich prednáškach, je škálovateľnosť algoritmu.
Všimli sme si aj ďalšie vlastnosti, ktoré musí spĺňať klastrovací algoritmus: nezávislosť výsledkov od poradia vstupných údajov; nezávislosť parametrov algoritmu od vstupných údajov.
Nedávno došlo k aktívnemu vývoju nových klastrovacích algoritmov schopných spracovávať super veľké databázy. Zameriavajú sa na škálovateľnosť. Takéto algoritmy zahŕňajú všeobecnú klastrovú reprezentáciu, ako aj vzorkovanie a používanie dátových štruktúr podporovaných základným DBMS.
Boli vyvinuté algoritmy, v ktorých sú metódy hierarchického zhlukovania integrované s inými metódami. Tieto algoritmy zahŕňajú: BIRCH, CURE, CHAMELEON, ROCK.
Algoritmus BIRCH (vyvážené iteratívne znižovanie a klastrovanie pomocou hierarchií)
Algoritmus navrhol Tian Zang a jeho kolegovia.
Vďaka zovšeobecneným reprezentáciám zhlukov sa rýchlosť zhlukovania zvyšuje, pričom algoritmus má veľké škálovanie.
Tento algoritmus implementuje dvojstupňový proces klastrovania.
Počas prvej etapy sa vytvorí predbežný súbor klastrov. V druhej fáze sa na identifikované klastre aplikujú ďalšie klastrovacie algoritmy - vhodné pre prácu v RAM.
V nasledujúcej analógii popisujúcej tento algoritmus je uvedený. Ak si každý dátový prvok predstavíme ako guľôčku ležiacu na povrchu stola, potom zhluky guľôčok možno „nahradiť“ tenisovými loptičkami a urobiť podrobnejšiu štúdiu zhlukov tenisových loptičiek. Počet guľôčok môže byť dosť veľký, ale priemer tenisových loptičiek môže byť zvolený tak, že v druhej fáze by bolo možné pomocou tradičných zhlukových algoritmov určiť skutočný zložitý tvar zhlukov.
Algoritmus WaveCluster
WaveCluster je zhlukovací algoritmus založený na vlnových transformáciách. Na začiatku algoritmu sa údaje zovšeobecnia vložením viacrozmernej mriežky do priestoru údajov. V ďalších krokoch algoritmu sa neanalyzujú jednotlivé body, ale zovšeobecnené charakteristiky bodov, ktoré spadajú do jednej bunky mriežky. V dôsledku tohto zovšeobecnenia potrebné informácie zmestí sa do RAM. V nasledujúcich krokoch algoritmus aplikuje vlnovú transformáciu na zovšeobecnené dáta na určenie zhlukov.
Hlavné vlastnosti WaveCluster:
Algoritmus CLARA vyvinuli Kaufmann a Rousseeuw v roku 1990 na zoskupovanie údajov vo veľkých databázach. Tento algoritmus je zabudovaný do štatistických analytických balíkov, ako je S+.
Stručne popíšme podstatu algoritmu. Algoritmus CLARA získava veľa vzoriek z databázy. Klastrovanie sa aplikuje na každú vzorku, najlepšie zhlukovanie je navrhnuté ako výstup algoritmu.
Pre veľké databázy je tento algoritmus efektívnejší ako algoritmus PAM. Účinnosť algoritmu závisí od súboru údajov vybratého ako vzorka. Dobré klastrovanie vo vybranej množine nemusí poskytnúť dobré klastrovanie v celej množine údajov.
Algoritmy Clarans, CURE, DBScan
Claransov algoritmus (Clustering Large Applications based on RANdomized Search) formuluje problém zhlukovania ako náhodné vyhľadávanie v grafe. Výsledkom tohto algoritmu je, že množina uzlov grafu je rozdelenie množiny údajov do počtu zhlukov špecifikovaných používateľom. „Kvalita“ výsledných zhlukov sa určuje pomocou funkcie kritéria. Algoritmus Clarans triedi všetky možné časti súboru údajov pri hľadaní prijateľného riešenia. Hľadanie riešenia sa zastaví v uzle, kde je dosiahnuté minimum medzi vopred určeným počtom lokálnych miním.
Z nových škálovateľných algoritmov možno spomenúť aj algoritmus CURE - hierarchický zhlukovací algoritmus a algoritmus DBScan, kde je koncept klastra formulovaný pomocou konceptu hustoty.
Hlavnou nevýhodou algoritmov BIRCH, Clarans, CURE, DBScan je skutočnosť, že vyžadujú špecifikáciu určitých prahových hodnôt hustoty bodov, čo nie je vždy prijateľné. Tieto obmedzenia sú spôsobené tým, že opísané algoritmy sú zamerané na veľmi veľké databázy a nemôžu využívať veľké výpočtové zdroje.
Mnoho výskumníkov aktívne pracuje na škálovateľných metódach, ktorých hlavnou úlohou je prekonať nedostatky súčasných algoritmov.

Adaptačné obdobie prvákov je dôležitým krokom v ich kognitívnom a učebnom procese. Rodičia, učitelia a...
Krok 3. Príprava na generovanie správy Na vytvorenie správy bude zákazník potrebovať nasledujúce údaje1. SHOZ 2....

Všetci kupujúci vedia, že monopol na trhu s elektronikou nie je vítaný. Preto nie je prekvapujúce, že slávny ...
Nie každý rozumie, ako poslať balík na dobierku. Tento jednoduchý postup má navyše svoj vlastný...

Nestáva sa často, aby bežný človek potreboval informácie o tom, ako si pečať vyrobiť sám. Ale stále sú chvíle, keď rady ...
Ak skôr bolo možné prítomnosť alebo neprítomnosť individuálneho podnikania potvrdiť iba návštevou dane ...

Jednou z kľúčových postáv na stavbe je majster stavebných a inštalačných prác. Organizuje...

Tajomník, zástupca alebo osobný asistent? Závisí od situácie! Zvážte požiadavky, zodpovednosti a podmienky,...

Oddelenie technickej kontroly QCD je nezávislým oddelením podniku v závode. Všetky...
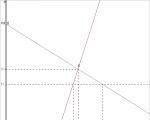
Funkcia dopytu po produkte má tvar: Qd = 15 - 2p Funkcia ponuky Qs = -2 + 3p Určte: 1. Rovnováha ...

Špecializácia Ekonomika a manažment v podniku (udelená kvalifikácia - ekonóm-manažér) dáva ...

Pamätáte si, že všetky javy a procesy ekonomickej činnosti podniku sú vzájomne prepojené a ...

Hľadáte prácu alebo si ju plánujete hľadať?Pomôže vám naša ukážka vyplnenia životopisu na pozíciu obchodný manažér ...

Ahoj! Tento článok vám ukáže, ako prejsť pohovorom. Dnes sa dozviete: Ako sa správať na...
Krok 3. Príprava na generovanie správy Na vytvorenie správy bude zákazník potrebovať nasledujúce údaje1. SHOZ 2....

Všetci kupujúci vedia, že monopol na trhu s elektronikou nie je vítaný. Preto nie je prekvapujúce, že...