Faktory ovplyvňujúce adaptáciu žiakov prvého stupňa
Adaptačné obdobie prvákov je dôležitým krokom v ich kognitívnom a učebnom procese. Rodičia, učitelia a...
IN ŠTATISTIKA implementované klasické metódy zhluková analýza, vrátane k-means, hierarchického klastrovania a metód združovania dvoch vstupov.
Dáta môžu prísť vo svojej pôvodnej podobe aj vo forme matice vzdialeností medzi objektmi.
Pozorovania a premenné môžu byť zoskupené pomocou rôznych vzdialeností (euklidovské, euklidovské štvorce, Manhattan, Čebyšev atď.) a rôznych pravidiel zoskupovania (jednoduché, úplné spojenie, nevážené a vážené priemery párových skupín atď.).
Pôvodný dátový súbor obsahuje nasledujúce informácie o vozidlách a ich vlastníkoch:
Účelom tejto analýzy je rozdeliť autá a ich majiteľov do tried, z ktorých každá zodpovedá určitej rizikovej skupine. Pozorovania patriace do jednej skupiny sa vyznačujú rovnakou pravdepodobnosťou poistnej udalosti, ktorú následne posudzuje poisťovateľ.
Použitie klastrovej analýzy na vyriešenie tohto problému je najúčinnejšie. Vo všeobecnom prípade je zhluková analýza navrhnutá tak, aby spájala niektoré objekty do tried (zhlukov) tak, aby tie najpodobnejšie spadali do jednej triedy a objekty rôznych tried sa od seba čo najviac líšili. Skóre podobnosti sa vypočíta vopred určeným spôsobom na základe údajov charakterizujúcich objekty.
Všetky klastrové algoritmy potrebujú odhadnúť vzdialenosti medzi zhlukami alebo objektmi a je jasné, že pri výpočte vzdialenosti je potrebné špecifikovať meraciu stupnicu.
Keďže rôzne merania používajú úplne odlišné typy váh, údaje musia byť štandardizované (v menu Údaje vybrať položku Štandardizovať), takže každá premenná bude mať priemer 0 a štandardnú odchýlku 1.
Tabuľka so štandardizovanými premennými je uvedená nižšie.

V prvej fáze zistíme, či autá tvoria „prirodzené“ zhluky, ktoré sa dajú pochopiť.
Poďme si vybrať zhluková analýza v ponuke Analýza - Viacrozmerná exploračná analýza na zobrazenie štartovacieho panela modulu zhluková analýza. V tomto dialógovom okne vyberte Hierarchická klasifikácia a stlačte OK.

Stlačíme tlačidlo Premenné, vyberte si Všetky, v teréne Objekty vyberte si Pozorovania (linky). Ako odborové pravidlo poznamenávame Metóda úplného odkazu, ako miera blízkosti - Euklidovská vzdialenosť. Stlačíme OK.

Metóda úplného prepojenia definuje vzdialenosť medzi klastrami ako najväčšiu vzdialenosť medzi akýmikoľvek dvoma objektmi v rôznych klastroch (t. j. „najvzdialenejší susedia“).
Miera blízkosti definovaná euklidovskou vzdialenosťou je geometrická vzdialenosť v n-rozmernom priestore a vypočíta sa takto:

Najdôležitejším výsledkom zhlukovania stromov je hierarchický strom. Stlačíme tlačidlo Vertikálny dendrogram.


Stromové diagramy sa môžu na prvý pohľad zdať trochu mätúce, ale po nejakom štúdiu sa stanú zrozumiteľnejšími. Diagram začína hore (pre vertikálny dendrogram) s každým autom vo svojom vlastnom zoskupení.
Keď sa začnete pohybovať nadol, autá, ktoré sú „bližšie k sebe“, sa spájajú a vytvárajú zhluky. Každý uzol vo vyššie uvedenom diagrame predstavuje spojenie dvoch alebo viacerých zhlukov, pričom poloha uzlov na zvislej osi určuje vzdialenosť, v ktorej boli príslušné zhluky kombinované.
Na základe vizuálneho znázornenia výsledkov možno predpokladať, že autá tvoria štyri prirodzené zhluky. Overme si tento predpoklad rozdelením počiatočných údajov metódou K mean do 4 zhlukov a skontrolujme významnosť rozdielu medzi získanými skupinami.
Na spúšťacom paneli modulu zhluková analýza vyberte si Klastrovanie pomocou K prostriedkov.

Stlačíme tlačidlo Premenné a vyberte si Všetky, v teréne Objekty vyberte si Pozorovania (linky), definujeme 4 klastre oddielov.

Metóda K-znamená je nasledovná: výpočty začínajú s k náhodne vybranými pozorovaniami (v našom prípade k=4), ktoré sa stanú centrami skupín, po ktorých sa zmení objektové zloženie zhlukov, aby sa minimalizovala variabilita v zhlukoch a maximalizovať variabilitu medzi klastrami.
Každé nasledujúce pozorovanie (K+1) patrí do skupiny, ktorej miera podobnosti s ťažiskom je minimálna.
Po zmene zloženia zhluku sa vypočíta nové ťažisko, najčastejšie ako vektor priemerov pre každý parameter. Algoritmus pokračuje, kým sa zloženie klastrov neprestane meniť.
Po získaní výsledkov klasifikácie môžete vypočítať priemernú hodnotu ukazovateľov pre každý klaster, aby ste mohli posúdiť, do akej miery sa navzájom líšia.
V okne Výsledky metódy K mean vyberte si Analýza rozptylu určiť významnosť rozdielu medzi výslednými zhlukami.

Takže hodnota p<0.05, что говорит о значимом различии.
Stlačíme tlačidlo Prvky klastra a vzdialenosti zobraziť pozorovania zahrnuté v každom z klastrov. Táto možnosť vám tiež umožňuje zobraziť euklidovské vzdialenosti objektov od stredov (stredné hodnoty) ich príslušných zhlukov.
Prvý klaster:

Druhý klaster:

Tretí klaster:
Štvrtý klaster:

Takže v každom zo štyroch klastrov sú objekty s podobným vplyvom na stratový proces.
Táto kapitola pokračuje v téme Vytváranie a analýza tabuliek. Odporúčame vám, aby ste si ho prečítali a potom začali čítať tento text a cvičenia STATISTICA.
Korešpondenčná analýza (v angličtine coirespondence analysis) je exploračná analytická metóda, ktorá umožňuje vizuálne a numericky skúmať štruktúru kontingenčných tabuliek veľkých rozmerov.
Korešpondenčná analýza ako prostriedok rozvoja mestských marketingových stratégií, 3. medzinárodná konferencia o najnovších pokrokoch vo vede o maloobchode a službách, str. 22-25, jún 1996, Telfs-Buchen (Osterreich) Werani, Thomas).
Aplikácie metódy sú známe v archeológii, textovej analýze, kde je dôležité skúmať dátové štruktúry (pozri Greenacre, M. J., 1993, Correspondence Analysis in Practice, London: Academic Press).
Tu je niekoľko ďalších príkladov:
Použitie korešpondenčnej analýzy v medicíne je spojené so štúdiom štruktúry komplexných tabuliek obsahujúcich indikátorové premenné ukazujúce prítomnosť alebo absenciu daného symptómu u pacienta. Tabuľky tohto druhu majú veľký rozmer a štúdium ich štruktúry je netriviálna úloha.
Úlohy vizualizácie zložitých objektov je možné preskúmať alebo aspoň priblížiť pomocou korešpondenčnej analýzy. Obrázok je viacrozmerná tabuľka a úlohou je nájsť rovinu, ktorá vám umožní čo najpresnejšie reprodukovať pôvodný obrázok.
Matematické základy metódy. Analýza korešpondencie sa opiera o štatistiku chí-kvadrát. Môžeme povedať, že ide o novú interpretáciu Pearsonovej chí-kvadrát štatistiky.
Metóda je v mnohom podobná faktorovej analýze, na rozdiel od nej sa tu však skúmajú kontingenčné tabuľky a kritériom kvality reprodukcie viacrozmernej tabuľky v priestore nižšej dimenzie je hodnota chí-kvadrát štatistiky. Neformálne možno o korešpondenčnej analýze hovoriť ako o faktorovej analýze kategorických údajov a považovať ju aj za metódu znižovania dimenzionality.
Takže riadky alebo stĺpce pôvodnej tabuľky sú reprezentované bodmi v priestore, medzi ktorými sa vypočítava vzdialenosť chí-kvadrát (podobne ako sa vypočítava štatistika chí-kvadrát na porovnanie pozorovaných a očakávaných frekvencií).
Ďalej musíte nájsť priestor malého rozmeru, zvyčajne dvojrozmerný, v ktorom sú vypočítané vzdialenosti minimálne skreslené, a v tomto zmysle čo najpresnejšie reprodukovať štruktúru pôvodnej tabuľky pri zachovaní vzťahov medzi prvkami (ak ak máte predstavu o metódach viacrozmerného škálovania, budete cítiť známu melódiu).
Vychádzame teda z bežnej krížovej tabuľky, teda tabuľky, v ktorej je prepojených niekoľko funkcií (viac informácií o krížových tabuľkách nájdete v kapitole Vytváranie a analýza tabuliek).
Predpokladajme, že existujú údaje o fajčiarskych návykoch zamestnancov určitej spoločnosti. Podobné údaje sú dostupné v súbore Smoking.sta, ktorý je súčasťou štandardnej sady príkladov systému STATISTICA.
V tejto tabuľke je atribút fajčenie spojený s atribútom position:
|
Skupina zamestnancov |
(1) Nefajčiari |
(2) Slabý fajčiar |
(3) Strední fajčiari |
(4) Silní fajčiari |
Celkom na riadok |
|
(1) Vyšší manažéri |
|||||
|
(2) Mladší manažéri |
|||||
|
(3) Vedúci zamestnanci |
|||||
|
(4) Mladší zamestnanci |
|||||
|
(5) Tajomníci |
|||||
|
Celkom na stĺpec |
Ide o jednoduchý krížový stôl s dvoma vstupmi. Najprv sa pozrime na struny.
Môžeme predpokladať, že prvé 4 čísla každého riadku tabuľky (okrajové frekvencie, to znamená, že posledný stĺpec sa neberie do úvahy) sú súradnicami riadku v 4-rozmernom priestore, čo znamená, že môžeme formálne vypočítať chí-kvadrát vzdialenosti medzi týmito bodmi (riadky tabuľky).
Pri daných hraničných frekvenciách je možné tieto body zobraziť v priestore o rozmere 3 (počet stupňov voľnosti je 3).
Je zrejmé, že čím menšia vzdialenosť, tým väčšia podobnosť medzi skupinami a naopak – čím väčšia vzdialenosť, tým väčší rozdiel.
Teraz predpokladajme, že je možné nájsť priestor s nižšou dimenziou, ako je dimenzia 2, ktorý predstavuje body riadkov, ktoré uchovávajú všetky alebo presnejšie takmer všetky informácie o rozdieloch medzi riadkami.
Tento prístup nemusí byť účinný pre malé stoly, ako je ten vyššie, ale je užitočný pre veľké tabuľky, ako sú tie, ktoré sa nachádzajú v prieskume trhu.
Napríklad, ak sa pri výbere 15 pív zaznamenajú preferencie 100 respondentov, potom ako výsledok aplikácie korešpondenčnej analýzy môže byť v rovine zastúpených 15 odrôd (bodov) (pozri analýzu predaja nižšie). Analýzou umiestnenia bodov uvidíte vzory pri výbere piva, ktoré budú užitočné pri vedení marketingovej kampane.
Korešpondenčná analýza používa určitý slang.
Hmotnosť. Pozorovania v tabuľke sú normalizované: vypočítajú sa relatívne frekvencie pre tabuľku, súčet všetkých prvkov tabuľky sa rovná 1 (každý prvok sa vydelí celkovým počtom pozorovaní, v tomto príklade 193). Vytvorí sa analóg dvojrozmernej hustoty rozloženia. Výsledná štandardizovaná tabuľka ukazuje, ako je hmota rozložená cez bunky tabuľky alebo cez body v priestore. V slangu korešpondenčnej analýzy sa súčty v riadkoch a stĺpcoch v matici relatívnej frekvencie nazývajú hmotnosť riadkov a stĺpcov.
Zotrvačnosť. Zotrvačnosť je definovaná ako Pearsonova hodnota chí-kvadrát pre tabuľku s dvoma vstupmi vydelená celkovým počtom pozorovaní. V tomto príklade: celková zotrvačnosť = 2/193 - 16,442.
Zotrvačnosť a profily radov a stĺpov. Ak sú riadky a stĺpce tabuľky úplne nezávislé (nie je medzi nimi žiadna súvislosť - napríklad fajčenie nezávisí od polohy), potom prvky tabuľky možno reprodukovať pomocou súčtov riadkov a stĺpcov alebo v terminológii korešpondenčnej analýzy pomocou riadkových a stĺpcových profilov (s použitím okrajových frekvencií (pozri kapitolu Vytváranie a analýza tabuliek pre Pearsonov Chi-Square Test a Fisherov presný test).
V súlade so známym vzorcom chí-kvadrát pre tabuľky s dvoma vstupmi sa očakávané frekvencie tabuľky, v ktorej sú stĺpce a riadky nezávislé, vypočítajú vynásobením zodpovedajúcich profilov stĺpcov a riadkov a vydelením výsledku celkovým súčtom.
Akákoľvek odchýlka od očakávaných hodnôt (podľa hypotézy úplnej nezávislosti premenných v riadkoch a stĺpcoch) prispeje k štatistike chí-kvadrát.
Korešpondenčnú analýzu možno považovať za rozklad štatistiky chí-kvadrát na jej zložky s cieľom nájsť najmenší rozmerový priestor, ktorý môže predstavovať odchýlky od očakávaných hodnôt (pozri tabuľku nižšie).
Tu sú tabuľky s očakávanými frekvenciami vypočítanými podľa hypotézy nezávislosti funkcií a pozorovanými frekvenciami, ako aj tabuľka príspevkov buniek k chí-kvadrát:

Tabuľka napríklad ukazuje, že počet nefajčiarskych juniorských zamestnancov je približne o 10 nižší, ako by sa očakávalo pri hypotéze nezávislosti. Na druhej strane je počet seniorov nefajčiarov o 9 vyšší, ako by sa očakávalo pri hypotéze nezávislosti atď.. Chceli by sme však mať všeobecný obraz.
Účelom korešpondenčnej analýzy je zhrnúť tieto odchýlky od očakávaných frekvencií nie v absolútnych, ale v relatívnych jednotkách.

Riadková a stĺpcová analýza. Namiesto riadkov tabuľky je možné uvažovať aj o stĺpcoch a reprezentovať ich ako body v priestore nižšej dimenzie, čo čo najpresnejšie reprodukuje podobnosť (a vzdialenosti) medzi relatívnymi frekvenciami stĺpcov tabuľky. Na rovnakom grafe môžete súčasne zobraziť stĺpce a riadky, ktoré predstavujú všetky informácie obsiahnuté v tabuľke s dvoma vstupmi. A táto možnosť je najzaujímavejšia, pretože umožňuje zmysluplnú analýzu výsledkov.
Výsledky. Výsledky korešpondenčnej analýzy sú zvyčajne prezentované vo forme grafov, ako je uvedené vyššie, a tiež vo forme tabuliek, ako napríklad:
|
Počet meraní |
Percento zotrvačnosti |
Kumulatívne percento |
Chí-kvadrát |
Pozrite sa na túto tabuľku. Ako si pamätáte, účelom analýzy je nájsť priestor nižšej dimenzie, ktorý obnoví tabuľku, pričom kritériom kvality je normalizovaná chí-kvadrát alebo zotrvačnosť. Je vidieť, že ak sa v uvažovanom príklade použije jednorozmerný priestor, teda jedna os, dá sa vysvetliť 87,76 % zotrvačnosti tabuľky.

Dva rozmery umožňujú vysvetliť 99,51 % zotrvačnosti.
Súradnice riadkov a stĺpcov. Zvážte výsledné súradnice v dvojrozmernom priestore.
|
Názov riadku |
Zmena 1 |
Zmena 2 |
|
vedúcich manažérov |
||
|
junior manažérov |
||
|
vedúci pracovníci |
||
|
mladších zamestnancov |
||
|
sekretárky |
Môžete to znázorniť na dvojrozmernom diagrame.

Zjavnou výhodou dvojrozmerného priestoru je, že čiary zobrazené ako blízke body sú blízko seba aj v relatívnych frekvenciách.
Vzhľadom na polohu bodov pozdĺž prvej osi si možno všimnúť, že sv. zamestnanci a sekretárky sú relatívne blízko v súradniciach. Ak si všímame riadky tabuľky relatívnych frekvencií (frekvencie sú štandardizované tak, že ich súčet pre každý riadok je 100 %), potom je podobnosť týchto dvoch skupín z hľadiska intenzity fajčenia zrejmá.
Úrok na riadok:
| Kategórie fajčiarov | |||||
|
Skupina zamestnancov |
(1) Nefajčiari |
(2) Slabý fajčiar |
(3) Strední fajčiari |
(4) Silní fajčiari |
Celkom na riadok |
|
(1) Vyšší manažéri |
|||||
|
(2) Mladší manažéri |
|||||
|
(3) Vedúci zamestnanci |
|||||
|
(4) Mladší zamestnanci |
|||||
|
(5) Tajomníci |
|||||
Konečným cieľom korešpondenčnej analýzy je interpretovať vektory vo výslednom nízkorozmernom priestore. Jedným zo spôsobov, ktorý môže pomôcť pri interpretácii výsledkov, je znázornenie stĺpcového grafu. Nasledujúca tabuľka zobrazuje súradnice stĺpcov:
|
Rozmer 1 |
Rozmer 2 |
|
|
Nefajčiari |
||
|
ľahkých fajčiarov |
||
|
Strední fajčiari |
||
|
Silní fajčiari |
Dá sa povedať, že prvá os udáva gradáciu intenzity fajčenia. Preto možno veľkú mieru podobnosti medzi senior manažérmi a tajomníkmi vysvetliť prítomnosťou veľkého počtu nefajčiarov v týchto skupinách.
Metrika súradnicového systému. V niektorých prípadoch sa termín vzdialenosť použil na označenie rozdielov medzi riadkami a stĺpcami matice relatívnej frekvencie, ktoré boli zas reprezentované v priestore nižšej dimenzie v dôsledku použitia metód korešpondenčnej analýzy.
V skutočnosti vzdialenosti reprezentované ako súradnice v priestore príslušnej dimenzie nie sú len euklidovské vzdialenosti vypočítané z relatívnych frekvencií stĺpcov a riadkov, ale niektoré vážené vzdialenosti.
Postup prispôsobenia hmotnosti je usporiadaný tak, že v priestore nižšieho rozmeru je metrikou chí-kvadrát metrika za predpokladu, že sa porovnávajú body riadkov a štandardizujú sa profily riadkov alebo sú štandardizované profily riadkov a stĺpcov, alebo porovnávajú sa stĺpcové body a štandardizujú sa stĺpové profily alebo štandardizácia riadkových a stĺpcových profilov.
Hodnotenie kvality riešenia. Existujú špeciálne štatistiky, ktoré pomáhajú vyhodnotiť kvalitu získaného riešenia. Všetky alebo väčšina bodov musí byť správne znázornená, to znamená, že vzdialenosti medzi nimi nesmú byť skreslené v dôsledku použitia postupu analýzy korešpondencie. Nasledujúca tabuľka zobrazuje výsledky výpočtu štatistiky na dostupných súradniciach riadkov na základe iba jednorozmerného riešenia v predchádzajúcom príklade (to znamená, že na rekonštrukciu profilov riadkov matice relatívnej frekvencie bola použitá iba jedna dimenzia).
Súradnice a príspevok k zotrvačnosti vedenia:
|
Týka sa zotrvačnosti. |
Miera zotrvačnosti.1 |
Kosínus**2 mes.1 |
||||
|
vedúcich manažérov |
||||||
|
junior manažérov |
||||||
|
vedúci pracovníci |
||||||
|
mladších zamestnancov |
||||||
|
sekretárky |
Súradnice. Prvý stĺpec tabuľky výsledkov obsahuje súradnice, ktorých interpretácia, ako už bolo uvedené, závisí od štandardizácie. Dimenzia je voliteľná používateľom (v tomto príklade sme zvolili jednorozmerný priestor) a súradnice sú zobrazené pre každú dimenziu (to znamená, že pre každú os je zobrazený jeden stĺpec súradníc).
Hmotnosť. Hmotnosť obsahuje súčty všetkých prvkov pre každý riadok matice relatívnej frekvencie (to znamená pre maticu, kde každý prvok obsahuje zodpovedajúcu hmotnosť, ako je uvedené vyššie).
Ak je možnosť vybratá ako metóda štandardizácie Profily riadkov alebo možnosť Riadkové a stĺpcové profily, ktorá je predvolene nastavená, potom sú súradnice riadku vypočítané z matice profilu riadka. Inými slovami, súradnice sú vypočítané na základe matice podmienených pravdepodobností uvedených v stĺpci Hmotnosť.
Kvalita. Stĺpec Kvalita obsahuje informácie o kvalite zobrazenia príslušného bodu čiary v súradnicovom systéme určenom zvolenou kótou. V predmetnej tabuľke bol vybraný iba jeden rozmer, preto čísla v stĺpci Kvalita sú kvalita reprezentácie výsledkov v jednorozmernom priestore. Je vidieť, že kvalita pre senior manažérov je veľmi nízka, ale vysoká pre senior a junior zamestnancov a sekretárky.
Znova si všimnite, že z výpočtového hľadiska je cieľom korešpondenčnej analýzy reprezentovať vzdialenosti medzi bodmi v priestore s nižšou dimenziou.
Ak sa použije maximálny rozmer (rovnajúci sa minimálnemu počtu riadkov a stĺpcov mínus jeden), všetky vzdialenosti sa dajú presne reprodukovať.
Kvalita bodu je definovaná ako pomer druhej mocniny vzdialenosti od daného bodu k začiatku, v priestore zvolenej dimenzie, k druhej mocnine vzdialenosti k počiatku, definovanému v priestore maximálneho rozmeru. (v tomto prípade sa ako metrika zvolí chí-kvadrát, ako už bolo spomenuté). Vo faktorovej analýze existuje podobný koncept všeobecnosti.
Kvalita vypočítaná systémom STATISTICA je nezávislá od zvolenej metódy štandardizácie a vždy používa predvolenú štandardizáciu (t. j. metrika vzdialenosti je chí-kvadrát a mieru kvality možno interpretovať ako podiel chí-kvadrát definovaných zodpovedajúcim riadkom v priestor zodpovedajúcej dimenzie).
Nízka kvalita znamená, že dostupný počet meraní dostatočne nereprezentuje zodpovedajúci riadok (stĺpec).
Relatívna zotrvačnosť. Kvalita bodu (pozri vyššie) predstavuje pomer príspevku daného bodu k celkovej zotrvačnosti (Chí-kvadrát), čo môže vysvetliť zvolený rozmer.
Kvalita neodpovedá na otázku, nakoľko a do akej miery príslušný bod skutočne prispieva k zotrvačnosti (hodnota chí-kvadrát).
Relatívna zotrvačnosť predstavuje podiel celkovej zotrvačnosti, ktorá patrí danému bodu a nezávisí od rozmeru zvoleného používateľom. Všimnite si, že konkrétne riešenie môže reprezentovať bod celkom dobre (vysoká kvalita), ale ten istý bod môže veľmi málo prispieť k celkovej zotrvačnosti (t. j. bodová čiara, ktorej prvky sú relatívne frekvencie, má podobnosť s nejakou čiarou, prvkami čo je priemer všetkých riadkov).
Relatívna zotrvačnosť pre každý rozmer. Tento stĺpec obsahuje relatívny príspevok zodpovedajúceho bodu čiary k hodnote zotrvačnosti v dôsledku zodpovedajúceho rozmeru. V prehľade je táto hodnota uvedená pre každý bod (riadok alebo stĺpec) a pre každú dimenziu.
Cosine**2 (kvalita alebo kvadratické korelácie s každou dimenziou). Tento stĺpec obsahuje kvalitu každého bodu vzhľadom na príslušný rozmer. Ak sčítame riadok po riadku prvky kosínusu ** 2 stĺpce pre každú dimenziu, potom dostaneme stĺpec hodnôt kvality, ktoré už boli uvedené vyššie (keďže dimenzia 1 bola zvolená v uvažovanom príklade, kosínus 2 sa zhoduje so stĺpcom Kvalita). Túto hodnotu možno interpretovať ako „koreláciu“ medzi zodpovedajúcim bodom a zodpovedajúcou dimenziou. Pojem kosínus ** 2 vznikol preto, že táto hodnota je druhou mocninou kosínusu uhla zvieraného daným bodom a príslušnou osou.
Ďalšie body. Zahrnutie ďalších bodov v riadkoch alebo stĺpcoch, ktoré pôvodne neboli zahrnuté do analýzy, môže pomôcť interpretovať výsledky. Je možné zahrnúť dodatočné body riadku aj ďalšie body stĺpca. Spolu s pôvodnými bodmi na tej istej mape môžete zobraziť aj ďalšie body. Zvážte napríklad nasledujúce výsledky:
|
Skupina zamestnancov |
Rozmer 1 |
Rozmer 2 |
|
vedúcich manažérov |
||
|
junior manažérov |
||
|
vedúci pracovníci |
||
|
mladších zamestnancov |
||
|
sekretárky |
||
|
Celoštátny priemer |
Táto tabuľka zobrazuje súradnice (pre dve dimenzie) vypočítané pre frekvenčnú tabuľku pozostávajúcu z klasifikácie stupňa závislosti od fajčenia medzi zamestnancami na rôznych pozíciách.
Riadok Národný priemer obsahuje súradnice dodatočného bodu, ktorým je priemerná úroveň (v percentách) vypočítaná pre rôzne národnosti fajčiarov. V tomto príklade ide o čisto modelové údaje.
Ak vytvoríte dvojrozmerný diagram skupín zamestnancov a národného priemeru, okamžite sa uistite, že tento dodatočný bod a skupina Tajomníci sú veľmi blízko seba a sú umiestnené na rovnakej strane horizontálnej súradnicovej osi s kategóriou Non -fajčiari (bod stĺpca). Inými slovami, vzorka uvedená v pôvodnej tabuľke frekvencií obsahuje viac fajčiarov, ako je národný priemer.
Zatiaľ čo rovnaký záver možno vyvodiť z pohľadu na pôvodnú krížovú tabuľku, vo väčších tabuľkách takéto závery samozrejme nie sú také zrejmé.
Kvalita zastúpenia dodatočných bodov.Ďalším zaujímavým výsledkom týkajúcim sa ďalších bodov je interpretácia kvality, reprezentácie pre danú dimenziu.
Účelom korešpondenčnej analýzy je opäť reprezentovať vzdialenosti medzi súradnicami riadkov alebo stĺpcov v priestore nižšej dimenzie. S vedomím, ako je tento problém vyriešený, je potrebné odpovedať na otázku, či je adekvátne (vzhľadom na vzdialenosti bodov v pôvodnom priestore) reprezentovať dodatočný bod v priestore zvolenej dimenzie. Nižšie sú uvedené štatistiky pre pôvodné body a pre dodatočný bodový národný priemer, ako sa vzťahuje na problém v 2D priestore.
Junior manažéri0,9998100,630578
Pripomeňme, že kvalita bodov-riadkov alebo stĺpcov je definovaná ako pomer druhej mocniny vzdialenosti od bodu k počiatku v priestore zmenšenej dimenzie ku štvorcu vzdialenosti od bodu k počiatku v pôvodnom priestore (ako metrický, ako už bolo uvedené, je zvolená vzdialenosť chí-kvadrát).
V určitom zmysle je kvalita veličina, ktorá vysvetľuje zlomok druhej mocniny vzdialenosti k ťažisku pôvodného mračna bodov.
Dodatočný bod čiary Národný priemer má kvalitu 0,76. To znamená, že daný bod je pomerne dobre reprezentovaný v dvojrozmernom priestore. Štatistika Cosine**2 je kvalita reprezentácie zodpovedajúceho bodového riadku v dôsledku výberu priestoru danej dimenzie (ak sčítame prvky stĺpcov Kosínus 2 pre každú dimenziu riadok po riadku, potom ako výsledkom sa dostaneme k hodnote kvality získanej skôr).
Grafická analýza výsledkov. Toto je najdôležitejšia časť analýzy. V podstate môžete zabudnúť na formálne kritériá kvality, ale na pochopenie grafov dodržujte niekoľko jednoduchých pravidiel.
Takže na grafe sú zobrazené body-riadky a body-stĺpce. Je dobré prezentovať tieto aj ďalšie body (napokon analyzujeme vzťahy medzi riadkami a stĺpcami tabuľky!).
Zvyčajne horizontálna os zodpovedá maximálnej zotrvačnosti. V blízkosti šípky je zobrazené percento celkovej zotrvačnosti vysvetlené touto vlastnou hodnotou. Často sú uvedené aj zodpovedajúce vlastné hodnoty prevzaté z tabuľky výsledkov. Priesečník dvoch osí je ťažiskom pozorovaných bodov, zodpovedajúcich priemerným profilom. Ak body patria do rovnakého typu, to znamená, že sú to riadky alebo stĺpce, potom čím menšia je vzdialenosť medzi nimi, tým je vzťah užší. Aby sa vytvoril vzťah medzi bodmi rôznych typov (medzi riadkami a stĺpcami), je potrebné zvážiť rohy medzi nimi s vrcholom v ťažisku.
Všeobecné pravidlo pre vizuálne hodnotenie stupňa závislosti je nasledovné.
Zvážte analýzu konkrétnych údajov v systéme STATISTICA.
Príklad 1 (analýza fajčiarov)
Krok 1. Spustite modul Analýza korešpondencie.
Na spúšťacom paneli modulu sú 2 typy analýz: korešpondenčná analýza a viacrozmerná korešpondenčná analýza.
Vyberte Analýza korešpondencie. Viacrozmerná korešpondenčná analýza bude diskutovaná v nasledujúcom príklade.
Krok 2 Otvorte dátový súbor smoking.sta v priečinku Príklady.


Súbor je už kontingenčnou tabuľkou, takže nie sú potrebné žiadne karty. Vyberte typ analýzy - Frekvencie bez zoskupenia premennej.
Krok 3. Kliknite na tlačidlo Premenné s frekvenciami a vyberte premenné na analýzu.
V tomto príklade vyberte všetky premenné.

Krok 4 Kliknite OK a spustite postup výpočtu. Na obrazovke sa zobrazí okno s výsledkami.

Krok 5 Zvážte výsledky pomocou možností v tomto okne.
Zvyčajne sa najskôr zvažujú grafy, pre ktoré existuje skupina tlačidiel Súradnicový graf.
Grafy sú k dispozícii pre riadky a stĺpce, ako aj pre riadky a stĺpce súčasne.
Vo voľbe sa nastavuje rozmer maximálneho priestoru Rozmer.
Najzaujímavejšia dimenzia je 2. Všimnite si, že na grafe, najmä ak je veľa údajov, sa môžu štítky navzájom prekrývať, takže možnosť Skráťte štítky.
Stlačte tretie tlačidlo 2M v dialógovom okne. Na obrazovke sa objaví graf:

Všimnite si, že na grafe sú uvedené oba faktory: skupina zamestnancov - riadky a intenzita fajčenia - stĺpce.
Spojte úsečkou kategóriu SENIORNÍ ZAMESTNANCI, ako aj kategóriu NIE s ťažiskom.
Výsledný uhol bude ostrý, čo v jazyku korešpondenčnej analýzy hovorí o prítomnosti pozitívnej korelácie medzi týmito znakmi (pozrite si pôvodnú tabuľku).
Súradnice riadkov a stĺpcov je možné zobraziť aj číselne pomocou tlačidla Súradnice riadkov a stĺpcov.

Pomocou tlačidla Vlastné hodnoty, môžete vidieť rozklad štatistiky chí-kvadrát z hľadiska vlastných hodnôt.
Možnosť Rozvrh iba vybrané merania umožňuje zobraziť súradnice bodov pozdĺž vybraných osí.

Skupina možností Zobraziť tabuľky v pravej časti okna umožňuje zobraziť pôvodnú a očakávanú kontingenčnú tabuľku, rozdiely medzi frekvenciami a ďalšie parametre vypočítané na základe hypotézy nezávislosti tabelovaných prvkov (pozri kapitolu Konštrukcia a analýza tabuliek, chí-kvadrát test).
Veľké tabuľky sa najlepšie skúmajú postupne a podľa potreby zavádzajú ďalšie premenné. Na tento účel sú k dispozícii nasledujúce možnosti: Pridať body riadku, Pridať body stĺpca.
Príklad 2 (analýza predaja)
V kapitole Analýza a zostavovanie tabuliek bol uvažovaný príklad súvisiaci s analýzou predaja. Aplikujme korešpondenčnú analýzu na dáta.
Predtým bolo poznamenané, že otázka, ktoré nákupy kupujúci uskutočnil, za predpokladu, že boli zakúpené 3 tovary, je zložitá.
Celkovo máme skutočne 21 produktov. Ak chcete zobraziť všetky kontingenčné tabuľky, musíte vykonať 21 × 20 × 19 = 7980 akcií. Počet akcií sa katastrofálne zvyšuje s nárastom tovaru a počtom funkcií. Aplikujme korešpondenčnú analýzu. Otvorme si dátový súbor s indikátorovými premennými označujúcimi zakúpený produkt.

Na spúšťacom paneli modulu vyberte Viacrozmerná korešpondenčná analýza.

Stanovme si podmienku pre výber pozorovaní.

Táto podmienka vám umožňuje vybrať kupujúcich, ktorí uskutočnili presne 3 nákupy.
Keďže máme do činenia s netabuľkovými údajmi, zvolíme typ analýzy Počiatočné údaje(vyžaduje sa karta).
Pre pohodlie ďalšieho grafického znázornenia volíme malý počet premenných. Vyberáme aj ďalšie premenné (pozri rámček nižšie).

Začnime výpočtový postup.

V okne, ktoré sa zobrazí Výsledky viacrozmernej korešpondenčnej analýzy pozrime sa na výsledky.
Pomocou tlačidla 2M sa zobrazí dvojrozmerný graf premenných.
V tomto grafe sú ďalšie premenné označené červenými bodkami, čo je vhodné na vizuálnu analýzu.
Všimnite si, že každá premenná má príznak 1, ak je položka zakúpená, a príznak 0, ak položka nie je zakúpená.
Pozrime sa na graf. Vyberme si napríklad blízke dvojice vlastností. 
V dôsledku toho dostaneme nasledovné:

Podobné štúdie možno vykonať pre iné údaje, ak neexistujú žiadne apriórne hypotézy o závislostiach v údajoch.
Data mining Frolov Timofey. BI-1102 Data mining je proces analytického skúmania veľkého množstva informácií (zvyčajne ekonomického charakteru) s cieľom identifikovať určité vzorce a systematické vzťahy medzi premennými, ktoré potom možno použiť na nové súbory údajov. Tento proces zahŕňa tri hlavné kroky: prieskum, vytvorenie modelu alebo štruktúry a jej testovanie. V ideálnom prípade s dostatkom údajov je možné zorganizovať iteračný postup na vytvorenie robustného modelu. Zároveň je v reálnej situácii prakticky nemožné otestovať ekonomický model v štádiu analýzy a preto prvotné výsledky majú charakter heuristiky, ktorú je možné použiť v rozhodovacom procese (napr. dostupné údaje naznačujú, že u žien sa frekvencia užívania liekov na spanie zvyšuje s vekom rýchlejšie ako u mužov. Metódy dolovania údajov sa stávajú čoraz obľúbenejšími ako nástroj na analýzu ekonomických informácií, najmä v prípadoch, keď sa predpokladá, že z existujúcich údajov možno získať poznatky na rozhodovanie v neistote. Aj keď sa v poslednom čase zvýšil záujem o vývoj nových metód analýzy údajov špeciálne navrhnutých pre podnikateľský sektor (napríklad klasifikačné stromy), vo všeobecnosti sú systémy dolovania údajov stále založené na klasických princípoch prieskumnej analýzy údajov (EDA) a vytváraní modelov. a používať rovnaké prístupy a metódy. Existuje však dôležitý rozdiel medzi postupom dolovania údajov a klasickou prieskumnou analýzou údajov (RAD): Systémy dolovania údajov sú viac zamerané na praktickú aplikáciu získaných výsledkov ako na objasnenie podstaty javu. Inými slovami, pri dolovaní dát nás veľmi nezaujíma konkrétny typ závislostí medzi premennými úlohy. Hlavným cieľom tohto postupu nie je objasnenie povahy tu zahrnutých funkcií alebo špecifickej formy interaktívnych viacrozmerných závislostí medzi premennými. Hlavná pozornosť je venovaná hľadaniu riešení, na základe ktorých by bolo možné zostaviť spoľahlivé prognózy. V oblasti dolovania údajov sa teda používa taký prístup k analýze údajov a získavaniu znalostí, ktorý je niekedy charakterizovaný slovami „čierna skrinka“. V tomto prípade sa používajú nielen klasické metódy prieskumnej analýzy údajov, ale aj metódy, ako sú neurónové siete, ktoré umožňujú vytvárať spoľahlivé predpovede bez špecifikovania konkrétneho typu tých závislostí, na ktorých je takáto predpoveď založená. Dátové dolovanie sa veľmi často interpretuje ako „zmes štatistík, metód umelej inteligencie (AI) a databázovej analýzy“ (Pregibon, 1997, s. 8) a až donedávna nebolo uznávané ako plnohodnotná oblasť záujem pre štatistikov a niekedy dokonca nazývaný „zadným dvorom štatistiky“ (Pregibon, 1997, s. 8). Pre svoj veľký praktický význam sa však tento problém v súčasnosti intenzívne rozvíja a vyvoláva veľký záujem (aj štatisticky) a dosiahli sa v ňom dôležité teoretické výsledky (pozri napr. materiály výročnej medzinárodnej konferencie on Knowledge Search and Data Mining (Medzinárodné konferencie o objavovaní znalostí a dolovaní dát), ktorých jedným z organizátorov bola v roku 1997 Americká štatistická asociácia). dátový sklad je miesto, kde sú uložené veľké viacrozmerné dátové súbory, čo uľahčuje získavanie a používanie informácií v analytických postupoch. Efektívna architektúra dátového skladu by mala byť organizovaná tak, aby bola integrálnou súčasťou informačného systému riadenia podniku (alebo aspoň spojená so všetkými dostupnými údajmi). V tomto prípade je potrebné použiť špeciálne technológie na prácu s podnikovými databázami (napríklad Oracle, Sybase, MS SQL Server). Vysokovýkonná technológia dátového skladu, ktorá umožňuje používateľom organizovať a efektívne využívať podnikovú databázu takmer neobmedzenej zložitosti, bola vyvinutá podnikovými systémami StatSoft a nazýva sa SENS a SEWSS). Termín OLAP (alebo FASMI - Rapid Analysis of Distributed Multidimensional Information) sa vzťahuje na metódy, ktoré umožňujú používateľom multidimenzionálnych databáz vytvárať v reálnom čase popisné a porovnávacie súhrny ("pohľady") údajov a získavať odpovede na rôzne ďalšie analytické otázky. Všimnite si, že napriek svojmu názvu táto metóda nezahŕňa interaktívne (v reálnom čase) spracovanie údajov; znamená to proces analýzy viacrozmerných databáz (ktoré môžu obsahovať najmä dynamicky aktualizované informácie) zostavovaním efektívnych „viacrozmerných“ dotazov na údaje rôznych typov. Nástroje OLAP môžu byť zabudované do podnikových (celopodnikových) databázových systémov a umožňujú analytikom a manažérom sledovať pokrok a výkonnosť ich podnikania alebo trhu ako celku (napríklad rôzne aspekty výrobného procesu alebo počet a kategórie transakcie uskutočnené rôznymi regiónmi). Analýza vykonávaná metódami OLAP sa môže pohybovať od jednoduchých (napr. frekvenčné tabuľky, popisné štatistiky, jednoduché tabuľky) až po pomerne zložité (napr. môže zahŕňať sezónne úpravy, odstránenie odľahlých hodnôt a iné čistenie údajov). Hoci metódy dolovania údajov možno použiť na akékoľvek informácie, nie na vopred spracované alebo dokonca neštruktúrované informácie, možno ich použiť aj na analýzu údajov a správ prijatých nástrojmi OLAP na účely hlbšieho výskumu, zvyčajne vo vyšších dimenziách. V tomto zmysle možno metódy dolovania údajov chápať ako alternatívny analytický prístup (ktorý slúži na iné účely ako OLAP) alebo ako analytické rozšírenie systémov OLAP. RAD a testovanie hypotéz Na rozdiel od tradičného testovania hypotéz, ktoré je určené na testovanie predchádzajúcich predpokladov o asociáciách medzi premennými (napr. „Existuje pozitívna korelácia medzi vekom osoby a jej/jej averziou k riziku“), sa používa Exploratory Data Analysis (EPA). nájsť asociácie.medzi premennými v situáciách, keď neexistujú žiadne (alebo nedostatočné) apriórne predstavy o povahe týchto vzťahov. Prieskumná analýza spravidla zvažuje a porovnáva veľké množstvo premenných a na nájdenie vzorcov sa používajú rôzne metódy. Výpočtové metódy RAD Výpočtové metódy prieskumnej analýzy údajov zahŕňajú základné štatistické metódy, ako aj zložitejšie, špeciálne vyvinuté metódy viacrozmernej analýzy, určené na hľadanie vzorov vo viacrozmerných údajoch. Základné metódy exploratívnej štatistickej analýzy. Medzi hlavné metódy prieskumnej štatistickej analýzy patrí postup analýzy rozdelenia premenných (napríklad na identifikáciu premenných s asymetrickým alebo negaussovským rozdelením vrátane bimodálnych), zobrazenie korelačných matíc s cieľom nájsť koeficienty, ktoré prekračujú určité prahové hodnoty (pozri predchádzajúci príklad) alebo analýza viacvstupových frekvenčných tabuliek (napríklad „vrstvené“ sekvenčné prezeranie kombinácií úrovní riadiacich premenných). Metódy viacrozmernej exploračnej analýzy. Metódy multivariačnej prieskumnej analýzy sú špecificky navrhnuté tak, aby našli vzory vo viacrozmerných údajoch (alebo sekvenciách jednorozmerných údajov). Patria sem: zhluková analýza, faktorová analýza, analýza liscriminantských funkcií, multivariačné škálovanie, log-lineárna analýza, kanonické korelácie, postupná lineárna a nelineárna (napríklad logit) regresia, korešpondenčná analýza, analýza časových radov. Neurálne siete. Táto trieda analytických metód je založená na myšlienke reprodukovania procesov učenia mysliacich bytostí (ako sa javia výskumníkom) a funkcií nervových buniek. Neurónové siete dokážu predpovedať budúce hodnoty premenných z už existujúcich hodnôt rovnakých alebo iných premenných, pričom predtým vykonali takzvaný proces učenia na základe dostupných údajov. Predbežné preskúmanie údajov môže slúžiť len ako prvý krok v procese analýzy údajov a kým sa výsledky neoveria (metódami krížovej validácie) na iných častiach databázy alebo na nezávislom súbore údajov, môžu sa vykonať maximálne ako hypotéza. Ak sú výsledky prieskumnej analýzy v prospech modelu, potom je možné jeho správnosť otestovať jeho aplikovaním na nové údaje a určením stupňa jeho konzistentnosti s údajmi (testovanie „predvídateľnosti“). Na rýchly výber rôznych podmnožín údajov (napríklad na čistenie, kontrolu atď.) a posúdenie spoľahlivosti výsledkov je vhodné použiť podmienky na výber pozorovaní.
1. Pojem data mining. Metódy dolovania údajov.
odpoveď:Data mining je identifikácia skrytých vzorcov alebo vzťahov medzi premennými vo veľkých poliach nespracovaných údajov. Spravidla sa člení na úlohy klasifikácie, modelovania a prognózovania. Proces automatického vyhľadávania vzorov vo veľkých súboroch údajov. Termín dolovanie údajov zaviedol Grigory Pyatetsky-Shapiro v roku 1989.
2. Koncept prieskumnej analýzy údajov. Aký je rozdiel medzi postupom dolovania údajov a metódami klasickej štatistickej analýzy údajov?
odpoveď:Prieskumná analýza údajov (EDA) sa používa na nájdenie systematických vzťahov medzi premennými v situáciách, keď neexistujú žiadne (alebo nedostatočné) apriórne predstavy o povahe týchto vzťahov.
Tradičné metódy analýzy údajov sa zameriavajú najmä na testovanie vopred formulovaných hypotéz a na „hrubú“ prieskumnú analýzu, pričom jedným z hlavných ustanovení dolovania údajov je hľadanie nezrejmých vzorcov.
3. Metódy grafickej exploračnej analýzy dát. Statistické nástroje pre grafickú prieskumnú analýzu dát.
odpoveď:Pomocou grafických metód môžete nájsť závislosti, trendy a offsety „skryté“ v neštruktúrovaných súboroch údajov.
Nástroje Statistica pre grafickú analýzu prieskumu: kategorizované radiálne grafy, histogramy (2D a 3D).
odpoveď:Tieto grafy sú sady 2D, 3D, ternárnych alebo n-rozmerných grafov (ako sú histogramy, bodové grafy, čiarové grafy, povrchy, koláčové grafy), jeden graf pre každú vybranú kategóriu (podmnožinu) pozorovaní.
5. Aké informácie o charaktere údajov možno získať z analýzy rozptylových grafov a kategorizovaných rozptylových grafov?
odpoveď:Bodové grafy sa bežne používajú na odhalenie povahy vzťahu medzi dvoma premennými (napríklad zisk a mzdy), pretože poskytujú oveľa viac informácií ako korelačný koeficient.
6. Aké informácie o charaktere údajov možno získať analýzou histogramov a kategorizovaných histogramov?
odpoveď:Histogramy sa používajú na štúdium rozdelenia frekvencií premenných hodnôt. Táto frekvenčná distribúcia udáva, ktoré konkrétne hodnoty alebo rozsahy hodnôt skúmanej premennej sa vyskytujú najčastejšie, nakoľko sa tieto hodnoty líšia, či sa väčšina pozorovaní nachádza blízko priemeru, či je rozdelenie symetrické alebo asymetrické, multimodálny (t. j. má dva alebo viac vrcholov), alebo unimodálny atď. Histogramy sa tiež používajú na porovnanie pozorovaných a teoretických alebo očakávaných rozdelení.
Kategorizované histogramy sú súbory histogramov zodpovedajúcich rôznym hodnotám jednej alebo viacerých kategorizačných premenných alebo súborom podmienok logickej kategorizácie.
7. Aký je zásadný rozdiel medzi kategorizovanými grafmi a maticovými grafmi v programe Statistica?
odpoveď:Maticové grafy tiež pozostávajú z viacerých grafov; tu však každá z nich je (alebo môže byť) založená na rovnakom súbore pozorovaní a grafy sú zostavené pre všetky kombinácie premenných z jedného alebo dvoch zoznamov. Kategorizované grafy vyžadujú rovnaký výber premenných ako nekategorizované grafy zodpovedajúceho typu (napríklad dve premenné pre bodový graf). Zároveň je pri kategorizovaných grafoch potrebné špecifikovať aspoň jednu zoskupovaciu premennú (alebo spôsob delenia pozorovaní do kategórií), ktorá by obsahovala informáciu o tom, či každé pozorovanie patrí do určitej podskupiny. Premenná zoskupenia nebude vynesená priamo do grafu (t. j. nebude vynesená), ale bude slúžiť ako kritérium na rozdelenie všetkých analyzovaných pozorovaní do samostatných podskupín. Pre každú skupinu (kategóriu) definovanú premennou zoskupenia sa vytvorí jeden graf.
8. Aké sú výhody a nevýhody grafických metód pre prieskumnú analýzu dát?
odpoveď:+ Viditeľnosť a jednoduchosť.
- Metódy uvádzajú približné hodnoty.
9. Aké analytické metódy analýzy primárnych prieskumných údajov poznáte?
odpoveď:Štatistické metódy, neurónové siete.
10. Ako otestovať hypotézu o zhode rozdelenia údajov vzorky s modelom normálneho rozdelenia v systéme Statistica?
odpoveď:Rozdelenie x 2 (chí-kvadrát) s n stupňami voľnosti je rozdelenie súčtu štvorcov n nezávislých štandardných normálnych náhodných premenných.
Chí-kvadrát je mierou rozdielu. Nastavte úroveň chyby na a=0,05. V súlade s tým, ak je hodnota p>a , potom je rozdelenie optimálne.
- pre testovanie hypotézy o zhode rozdelenia údajov vzorky s modelom normálneho rozdelenia pomocou chí-kvadrát testu zvoľte položku menu Štatistika/Distribučné tvarovky. Potom v dialógovom okne Fitting sporné rozdelenie nastavte typ teoretického rozdelenia - Normálne, vyberte premennú - Premenné, nastavte parametre analýzy - Parametre.
11. Aké hlavné štatistické charakteristiky kvantitatívnych premenných poznáte? Ich popis a interpretácia z hľadiska riešeného problému.
odpoveď:Hlavné štatistické charakteristiky kvantitatívnych premenných:
matematické očakávania (priemerná produkcia medzi podnikmi)
medián
štandardná odchýlka (druhá odmocnina rozptylu)
rozptyl (miera šírenia danej náhodnej premennej, t. j. jej odchýlky od matematického očakávania)
koeficient asymetrie (Posunutie vzhľadom na stred symetrie určíme podľa pravidla: ak B1>0, tak posunutie doľava, inak - doprava.)
koeficient špičatosti (blízko normálnemu rozdeleniu)
minimálna hodnota vzorky, maximálna hodnota vzorky,
rozhadzovať
Čiastočný korelačný koeficient (meria stupeň tesnosti medzi premennými za predpokladu, že hodnoty ostatných premenných sú fixné na konštantnej úrovni).
kvalita:
Spearmanov koeficient poradovej korelácie (používa sa na účely štatistického skúmania vzťahu medzi javmi. Skúmané objekty sú zoradené vo vzťahu k nejakému atribútu, t. j. sú im priradené poradové čísla – hodnosti.)
1. Aivazyan S.A., Enyukov I.S., Meshalkin L.D. Aplikovaná štatistika: Základy modelovania a primárneho spracovania údajov. - M.: "Financie a štatistika", 1983. - 471 s.
2. Borovikov V.P. štatistiky. Umenie počítačovej analýzy dát: Pre profesionálov. 2. vyd. - Petrohrad: Peter, 2003. - 688 s.
3. Borovikov V.P., Borovikov I.P. Statistica - Štatistická analýza a spracovanie dát v prostredí Windows. - M.: "Filin", 1997. - 608 s.
4. Elektronická učebnica StatSoft o analýze dát.
Prieskumná dátová analýza (ADA; Prieskumná dátová analýza) sa používa, keď na jednej strane má výskumník k dispozícii tabuľku viacrozmerných dát a na druhej strane a priori informácie o fyzickom (kauzálnom) mechanizme na generovanie týchto dát. chýbajúce alebo neúplné. V tejto situácii môže RAD pomôcť v kompaktnom a zrozumiteľnom opise dátovej štruktúry pre výskumníka (napríklad vo forme vizuálnej reprezentácie tejto štruktúry), z ktorej už môže „zacieliť“ nastoliť otázku podrobnejšie štúdium údajov pomocou jednej alebo druhej sekcie štatistickej analýzy, zdôvodnenie štruktúry získaných údajov pomocou prístroja na testovanie štatistických hypotéz a prípadne aj vyvodenie záverov o kauzálnom údajovom modeli. Tento krok sa nazýva „analýza konfirmačných údajov“. Niekedy môže byť odhalenie dátovej štruktúry pomocou RAD aj konečnou fázou analýzy. Na druhej strane, množstvo metód RAD možno považovať aj za metódy na prípravu údajov na následné štatistické spracovanie bez akéhokoľvek štúdia štruktúry údajov, ktoré sa má vykonávať v ďalších fázach.
V tomto prípade hrá štádium RAD úlohu určitého štádia prekódovania a transformácie údajov (napríklad zmenšením rozmeru) do formy vhodnej pre následnú analýzu. V každom prípade, na akýkoľvek účel sa používajú metódy RAD, hlavnou úlohou je prejsť ku kompaktnému popisu údajov pri čo najúplnejšom zachovaní podstatných aspektov informácií obsiahnutých v pôvodných údajoch. Je tiež dôležité, aby bol popis pre používateľa zrozumiteľný. Termín „explorative data analysis“ prvýkrát zaviedol J. Tukey v roku 1962.
Modely štruktúry viacrozmerných dát. Nech sú údaje uvedené ako dátová matica. Objekty môžu byť reprezentované ako body vo viacrozmernom (p-rozmernom) priestore. Na opísanie štruktúry tohto súboru bodov používa RAD jeden z nasledujúcich štatistických modelov:
a) model mračna bodov približne elipsoidnej konfigurácie;
b) klastrový model, teda súbor niekoľkých „oblakov“ bodov, ktoré sú od seba dostatočne vzdialené;
c) model „kontaminácie“ (kompaktný mrak bodov a zároveň vzdialené odľahlé hodnoty);
d) model podopretia bodov ako varieta (lineárna alebo nelineárna) menšieho rozmeru ako bol pôvodný; typický príklad je vzorka z degenerovanej distribúcie;
e) diskriminačný model, kedy sú body nejakým spôsobom rozdelené do viacerých skupín a uvádza sa informácia o ich príslušnosti k určitej skupine.
V rámci modelu možno uvažovať aj o regresnom modeli, keď zodpovedajúca varieta pripúšťa funkčnú reprezentáciu , kde sú dve skupiny premenných z pôvodnej množiny (premenné z sa potom nazývajú prediktívne premenné a z prediktívne premenné); - chyba predpovede.
Samozrejme, reálne dáta môžu zvyčajne len približne sledovať tieto modely, navyše dátová štruktúra nemusí ani približne zodpovedať žiadnemu z modelov uvedených v popise.
Modely na popis štruktúry závislostí. V priestore premenných, na popis štruktúry závislostí medzi premennými, často používame nasledujúce modely: model nezávislých premenných, model lineárne závislých premenných, stromový model závislosti, faktoriálny model pre lineárne závislé premenné klastrový model (ľubovoľné väzbové koeficienty), hierarchický model závislosti.
Hlavné metodologické techniky pri vykonávaní prieskumnej analýzy údajov. Metódy analýzy a interpretácie výsledkov do značnej miery závisia od zvolenej metódy spracovania. Je však možné vyčleniť niekoľko účinných metód a prístupov k analýze výsledkov, ktoré sú najvšeobecnejšie a do značnej miery určujú špecifiká samotnej prieskumnej analýzy, odlišujú ju od ostatných fáz štatistického spracovania. Ide o vizualizáciu údajov a manipuláciu s nimi na základe grafického zobrazenia; používanie aparátu aktívnych a názorných premenných; transformácia dát, uľahčenie identifikácie štruktúr, analýza rezíduí.


Adaptačné obdobie prvákov je dôležitým krokom v ich kognitívnom a učebnom procese. Rodičia, učitelia a...
Krok 3. Príprava na generovanie správy Na vytvorenie správy bude zákazník potrebovať nasledujúce údaje1. SHOZ 2....

Všetci kupujúci vedia, že monopol na trhu s elektronikou nie je vítaný. Preto nie je prekvapujúce, že slávny ...
Nie každý rozumie, ako poslať balík na dobierku. Tento jednoduchý postup má navyše svoj vlastný...

Nestáva sa často, aby bežný človek potreboval informácie o tom, ako si pečať vyrobiť sám. Ale stále sú chvíle, keď rady ...
Ak skôr bolo možné prítomnosť alebo neprítomnosť individuálneho podnikania potvrdiť iba návštevou dane ...

Jednou z kľúčových postáv na stavbe je majster stavebných a inštalačných prác. Organizuje...

Tajomník, zástupca alebo osobný asistent? Závisí od situácie! Zvážte požiadavky, zodpovednosti a podmienky,...

Oddelenie technickej kontroly QCD je nezávislým oddelením podniku v závode. Všetky...
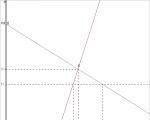
Funkcia dopytu po produkte má tvar: Qd = 15 - 2p Funkcia ponuky Qs = -2 + 3p Určte: 1. Rovnováha ...

Špecializácia Ekonomika a manažment v podniku (udelená kvalifikácia - ekonóm-manažér) dáva ...

Pamätáte si, že všetky javy a procesy ekonomickej činnosti podniku sú vzájomne prepojené a ...

Hľadáte prácu alebo si ju plánujete hľadať?Pomôže vám naša ukážka vyplnenia životopisu na pozíciu obchodný manažér ...

Ahoj! Tento článok vám ukáže, ako prejsť pohovorom. Dnes sa dozviete: Ako sa správať na...

Webová stránka Ezhednevnik zostavuje vrcholy úspešných a vplyvných bieloruských podnikateľov od roku 2007, dnes ...

Čo ponúka 2019 Small Business Startup Grant a ako môžem požiadať? Otvorenie podniku pre mnohých...